Buffer
在讲解Vert.x中的数据类型io.vertx.core.buffer.Buffer之前,先带您回顾一下java.nio.Buffer,这是理解Buffer的基础,如果理解了它的原理和使用方法,大家只需要了解使用场景,就可以掌握Vert.x中的Buffer了。
1. Buffer基本概念
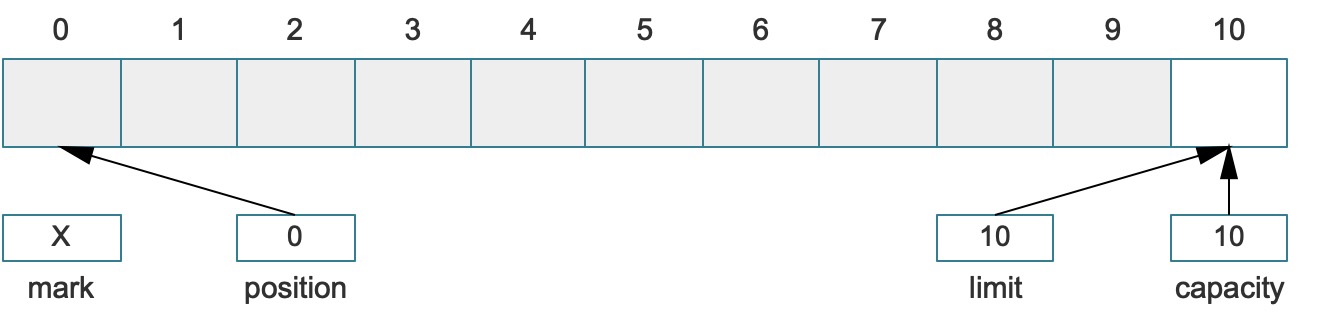
Buffer的数据结构是一个保存了原始数据的数组,一般我们翻译成缓冲区,它是一个用于存储速度不同的设备或优先级不同的设备之间传输数据的区域,使用了缓冲区过后,进程/线程之间的相互等待变少了,从而使两个不对等速度的设备之间的数据传输变得平滑,而不会间断。Java语言中的Buffer有四个主要属性:
- 容量(Capacity):容量描述了这个缓冲区的初始尺寸、能存储多少数据、描述了当前缓冲区能存储元素的最大值,是在创建Buffer的时候指定的,一旦指定就不可更改。
- 限制(Limit):不能进行读写的缓冲区的第一个元素索引,——又表示当前缓冲区已经存储的活动元素(Active Element)的数量。
- 位置(Position):下一个需要进行读写元素的索引,当Buffer缓冲区调用
get()和set()方法时会自动更新Position的值。 - 标记(Mark):一个可记忆的Position位置的值,当调用mark()方法的时候会执行
mark = position,一旦调用reset()的时候就执行position = mark,和Position不一样的是,必须要执行重置操作过后mark才会存在,最初的mark值是不存在的(初始值-1)。
这几个属性的关系如下:
0 <= mark <= position <= limit <= capacity
参考下图:
1.1. 访问Buffer
一般情况Buffer可以管理很多元素,通常在编程过程中,我们只关心活跃元素。例如上图所示:小于limit位置的这些元素是真正在IO读写过程中所需要的,当Buffer类调用了put()方法时,就会在原始Buffer中插入某个元素,如果调用了get()方法就会读取该位置的元素。这里的put和get就是访问Buffer的常用API。实际上访问Buffer存在两种模式:
- 相对访问:相对访问中,不使用索引(
index),直接使用位置(position)作为基础,系统自动计算调用结果。访问过程中,如果位置的值大于限制的值(position > limit),就会抛出缓冲区越界异常——java.nio.BufferOverflowException。 - 绝对版本:绝对访问中,位置(
position)的值不会受到影响,开发人员使用索引(index)进行访问,如果索引越界就会抛出异常索引越界异常——java.lang.IndexOutOfBoundsException。
1.2. 填充Buffer(put)
先看一段代码:
package io.vertx.up._02.buffer;
import java.nio.ByteBuffer;
public class BufferFirst {
public static void main(final String[] args) {
final ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.put((byte) 'H')
.put((byte) 'e')
.put((byte) 'l')
.put((byte) 'l')
.put((byte) 'o');
System.out.println(buffer);
}
}
执行上述代码,可以看到buffer变量的输出,pos就是位置,lim就是限制,cap就是容量:
java.nio.HeapByteBuffer[pos=5 lim=10 cap=10]
最终生成的Buffer结构如下:
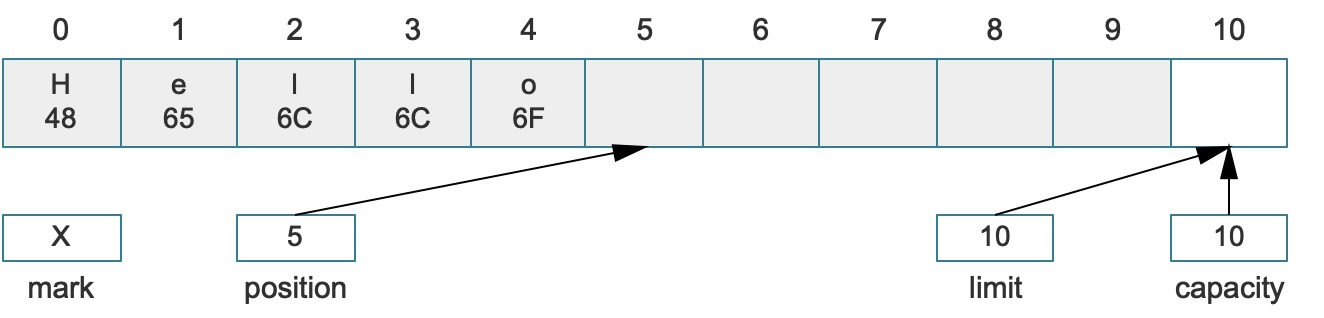
图中的H 48中存储的48是H在计算机中的ASCII值,在Java语言中,每个字符的基础类型是char,该类型就是整数,我们代码中使用了ByteBuffer,所以填充时使用(byte)'H'进行强制转换,由于char和byte在Java中都是整数类型,所以这种转型是合法的,如果不使用强制转换编译器会报错。
但是,Java语言中所有的字符格式采用了16位的Unicode格式,而byte的范围是二进制的-128 ~ 127,只有8位,如果您使用的字符超过了这个长度,那么填充的时候就会出现数据丢失,如下边的代码:
final ByteBuffer buffer2 = ByteBuffer.allocate(10);
buffer2.put((byte) '你');
所以在这种情况下,需要使用CharBuffer代替ByteBuffer或者换成其他类型的缓冲区。上述例子演示了相对调用,若使用绝对调用如:
package io.vertx.up._02.buffer;
import java.nio.ByteBuffer;
public class BufferAbs {
public static void main(final String[] args) {
final ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.put(3, (byte) 'M')
.put((byte) 'w');
final byte[] result = buffer.array();
for (int idx = 0; idx < result.length; idx++) {
System.out.print(idx + ":" + (char) result[idx] + ", ");
}
}
}
注意:绝对版本的调用中,由于使用了索引值,只要索引不越界,那么就不会引起position的变化,那么上述的代码在执行后结果如下:
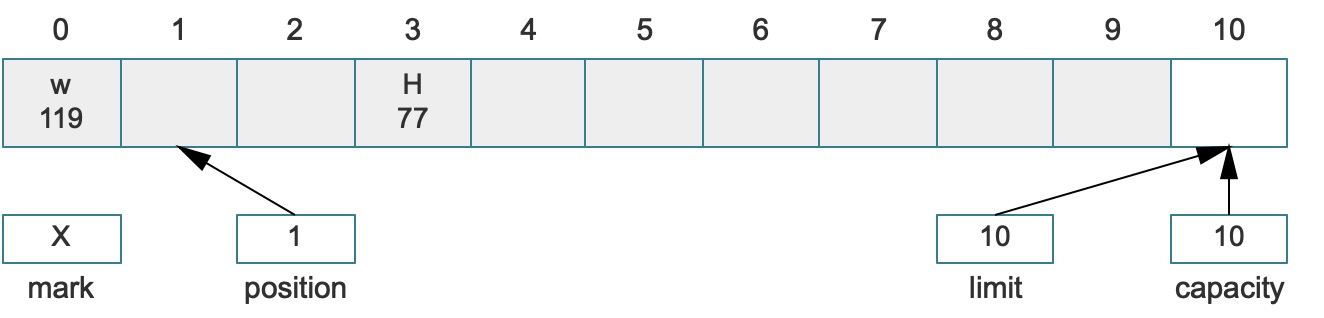
也就是说,如果同时使用相对访问和绝对方法,那么会出现一个小问题,如上图所示,若在后续代码中继续使用相对访问,当
position的位置移动到先前设置的索引(index = 3)位置时,相对调用的填充方法会将原始的值(H)覆盖掉。
1.3. 反转Buffer(flip)
在编程过程中填充了一个Buffer过后,系统会对该Buffer进行消耗(Draining),一般是将该Buffer传入一个通道(Channel)内然后输出。当Buffer传入某个通道后,该通道会调用get()方法来读取数据,但由于Buffer中的数据是有序存储,在填充过后,position已经发生了改变,这种情况下如果直接读取数据就会从position开始,直接开始就会导致读取数据不正确。如上述的Hello那个例子,buffer本身的position已经设置成5了,如果直接读取数据,会导致后续读取到的数据都是空的,那么思考一个问题,有没有一种办法在不清空数据的情况下重置position——这就是本节将要介绍的flip操作。
先看看flip()的源代码:
public final Buffer flip() {
limit = position;
position = 0;
mark = -1;
return this;
}
为了让您更直观,这里我提供两张变化图,分别是flip()之前和之后的存储结构。在调用flip()之前:
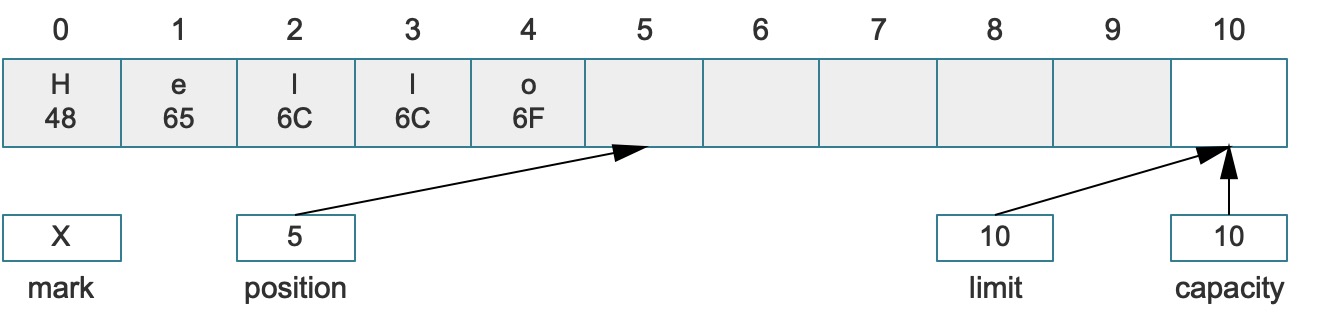
如果调用了flip()方法,就变成了如下:

其实flip()方法等价于调用了:buffer.limit(buffer.position()).position(0);。综上所述,经过了flip操作后,逻辑上思考,确实Buffer已经被反转了,此时通道类(Channel)读取Buffer时又会从0开始,也就是H字符,而不会导致数据读取出错。——与其说是“反转”,不如说是“重置”,和真正的重置不同的是这个操作并不会清空数据,仅仅是重设position和limit属性,以保证通道(Channel)类可以正确读取到数据。
我在编程过程中还看到了另外一个API:rewind方法,该方法和flip是类似的,但是它不会改变limit,仅仅只是重设position和mark。最后需要说明的一点就是flip不要重复调用,如果连续调用两次,第二次的limit会直接设置成0,那么在读取数据的时候就会直接抛出缓冲区越界异常——java.nio.BufferOverflowException。下图是rewind()调用的结果,提供给您参考:

rewind() 方法的起点是第一张图,而不是调用了flip()方法之后!
1.4. 消费Buffer(draining)
如果理解了前文提到的Buffer的各种核心操作以及原理,那么消费过程就变得简单了,这里再强调一次,当Buffer数据填充过后,若要执行数据的消费,是通过通道(Channel)来处理数据的,读取则会在get()方法之前先调用flip()方法。在Buffer中有一个hasRemaining()的方法,在读取数据的过程中,该方法可以判断position是否达到了limit,由于超越过后会抛异常,所以这个方法通常在迭代过程中会使用到,不仅仅如此,remaining()方法可以返回当前的limit值。
参考下边代码理解如何消费:
package io.vertx.up._02.buffer;
import java.nio.CharBuffer;
public class BufferDrain {
private static final
String[] strings = {
"A random string value",
"The product of an infinite number of monkeys",
"Hey hey we're the Monkees",
"Opening act for the Monkees: Jimi Hendrix",
"'Scuse me while I kiss this fly'",
"Help Me! Help Me!"
};
private static int index = 0;
private static void drainBuffer(final CharBuffer buffer) {
while (buffer.hasRemaining()) {
System.out.print(buffer.get());
}
System.out.println();
}
private static boolean fillBuffer(final CharBuffer buffer) {
if (index >= strings.length) return false;
final String string = strings[index++];
for (int i = 0; i < string.length(); i++)
buffer.put(string.charAt(i));
return true;
}
public static void main(final String[] args) {
final CharBuffer buffer = CharBuffer.allocate(100);
while (fillBuffer(buffer)) {
buffer.flip();
drainBuffer(buffer);
buffer.clear();
}
}
}
1.5. 压缩Buffer(compacting)
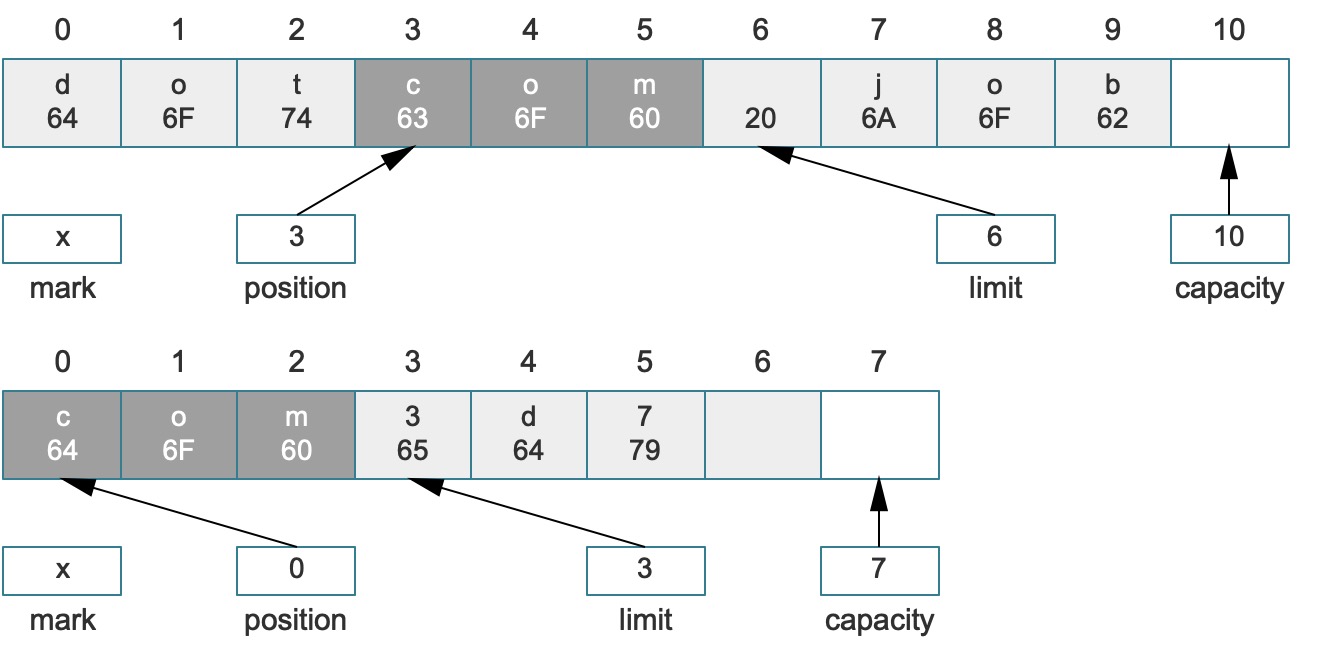
大部分场景中,应用程序往往只需要读取缓冲区中的部分内容而不是全部,而有时候又需要从原来的位置重新填充,这种情况下原始的Buffer中会遗留很多无效数据。为了直接读取到有效数据并且可节省存储空间,就需要使用compact()操作来压缩缓冲区,先看下边的截图,理解compact()做了些什么?
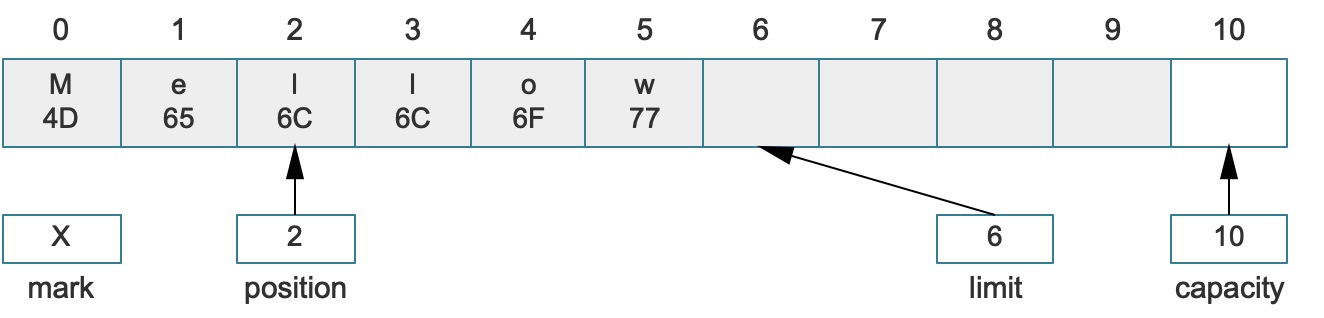
如果上述结构调用了compact()方法,就会变成:
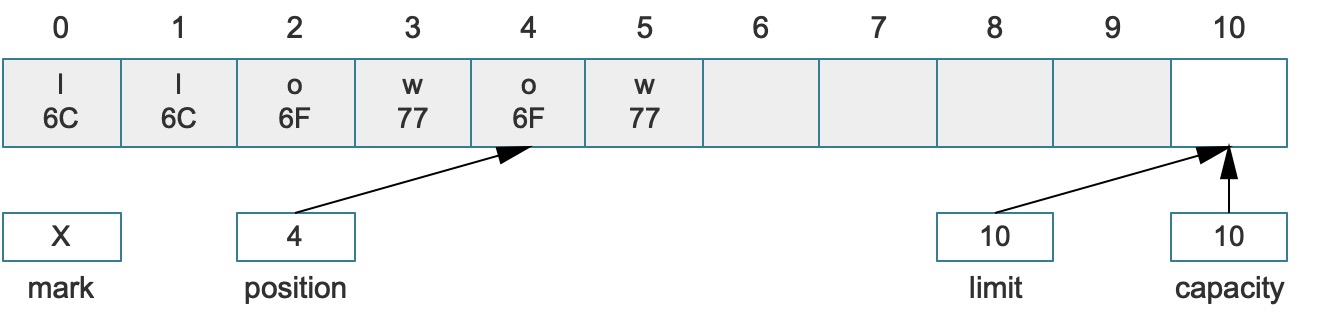
初次接触Buffer的您可能不太明白上边的变化,仔细分析一下:
- 在
compact()调用之前,Buffer中的Me就属于上边提到的无效数据,此时,如果Buffer不执行flip或rewind,那么继续操作时,可用的数据只有llow四个字符(索引2 ~ 5)。 - 而
compact()执行之后,将原始的llow字符拷贝到了当前缓冲区的最前面(索引0 ~ 3),而position设置到了索引4中,而limit设置成了容量相等。 - 执行该方法过后,这个Buffer可以被继续填充(并且填充至容量),也就是说
compact()操作放弃了原来Buffer已经消费过的元素,而在调用之后,如果直接读取数据,仍然可以读取到原始的数据(索引4 ~ 5),而此时这个数据是无效数据,它已经被移动到2 ~ 3的位置。
简单说,compact操作将position和limit之间的数据直接复制到了开始位置,从而为后续的put/read滕让空间,position的值设置成第一个合法的可写位置,limit设置成最大容量,通常这个操作是为了写数据量身订造的,细心的您会发现,继续读数据反而读取不了想要的数据信息!
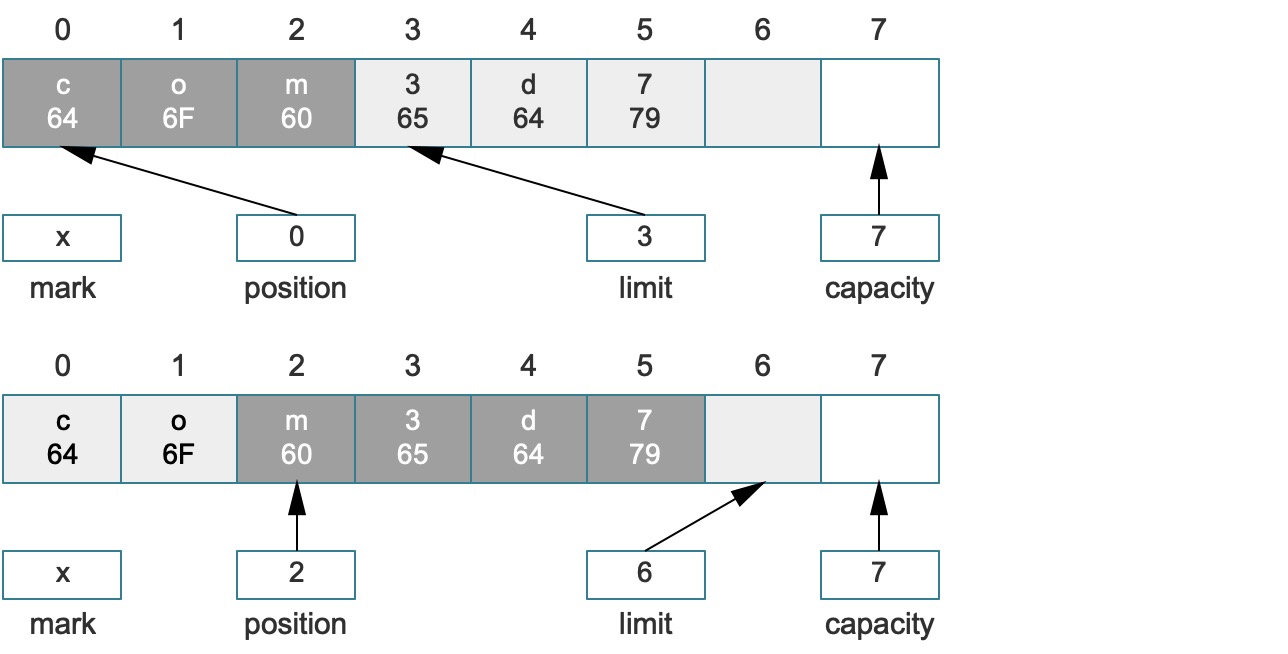
比如场景:若有一个缓冲区需要些数据,write() 方法的非阻塞调用只会写出它能够发送的数据而不会阻塞等待所有的数据都发送完成才执行,因此write()方法不一定会将缓冲区中的所有数据都发出去,假设此时需要调用 read 方法读取数据——在缓冲区中读取没有发送的数据和后面新写入的数据,此时的处理方法就是:position = limit和limit = capacity。当然在读入了新数据,再次调用write()方法之前还需要将这些值还原,这样做会使得缓冲区耗尽,此时若调用compact就可以避免这种情况发生。
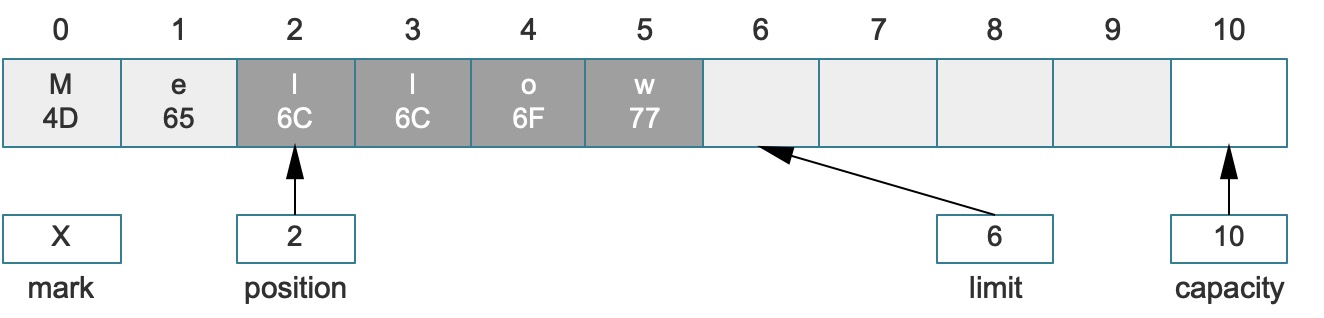
比如上边最后一个图的示例,它实际上是写就绪状态,可以继续调用put写数据,如下图:

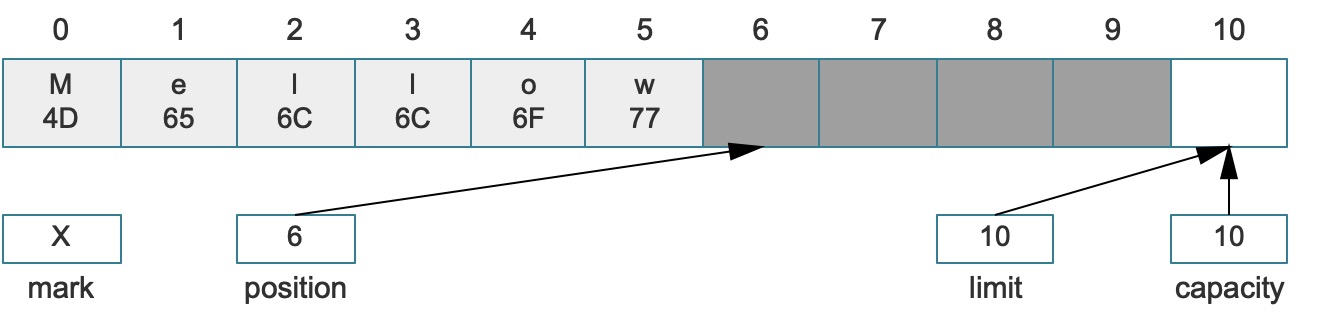
而深色区域就是合法可写区域,如果想要将该缓冲区设置成读就绪状态,可以直接调用flip转换成如下结构,深色区域就是合法可读区域:

这样,压缩做的事情就一目了然了,而在这种情况下,处理过后多余的索引(4 ~ 5)的错误数据出现了只可写不可读的状态,这种状态也符合我们的预期,所以即使不清空这两个数据对后续的缓冲区操作也不会产生任何影响。对比原始缓冲区的写就绪和读就绪的数据结构,就可以看到读写区域已经被压缩了,这也是这个方法的含义,原始缓冲区的读就绪状态如:
写就绪状态如:
1.6. 标记Buffer(marking)
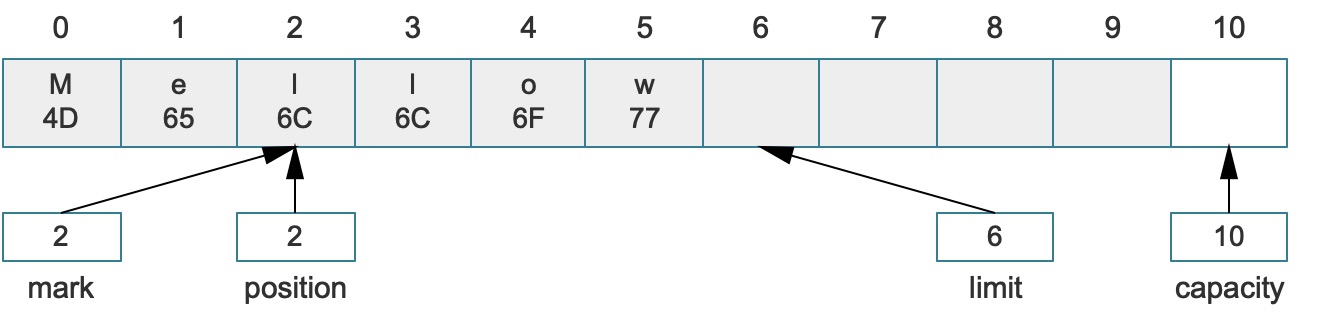
到目前为止,主要介绍了Buffer的四个核心属性中的三个:position、limit、capacity,本章节介绍最后一个属性mark,即标记。标记的方法可以调用mark()让这个缓冲区记住某个位置,并且让position在返回的时候不返回索引0而是返回标记的位置。而mark()方法有一个逆操作,就是reset(),唯一的限制就是在调用reset()之前,mark属性值必须存在(最少调用过一次mark()),否则mark属性是初始值-1,系统会抛出java.nio.InvalidMarkException异常。
- mark():设置
mark = position。 - reset():设置
position = mark(mark必须大于等于0)。
接下来看一段代码:
package io.vertx.up._02.buffer;
import java.nio.ByteBuffer;
public class BufferMark {
public static void main(final String[] args) {
final ByteBuffer buffer = ByteBuffer.allocate(10);
buffer.put((byte) 'H').put((byte) 'e').put((byte) 'l').put((byte) 'l').put((byte) 'o');
buffer.put(0, (byte) 'M').put((byte) 'w');
// 主要关注这一行的调用
buffer.position(2).mark().position(4);
}
}
上述代码执行后,会生成下图的Buffer结构:
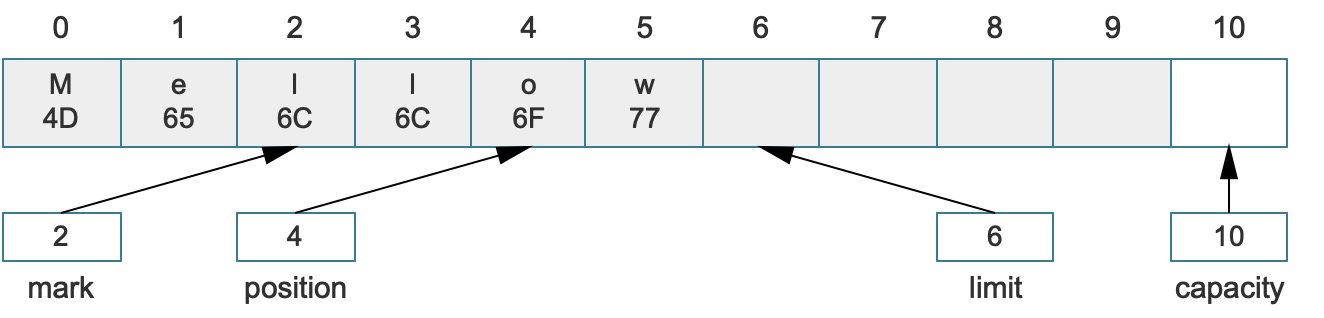
如果在这个基础之上调用了reset()方法,结果如下:
1.7. 比较Buffer(comparing)
逻辑比较操作是编程过程中常用的操作,而缓冲区的比较相对而言会变得更加复杂,毕竟它有独一无二的数据结构,并且它内置虽然是一个数组,但和数组有本质上的区别。两个Buffer的比较使用equals方法,它的逻辑如下:
- 两个对象必须是同类型的,如
CharBuffer不可以和ByteBuffer比较,否则无法通过编译。 - 两个Buffer对象position到limit之间的元素数量(
remaining()返回值)必须相同,两个Buffer的容量capacity可以不同,而且两个Buffer的索引位置也可以不同。 - 在
remaining段的初始位置到结束位置的每一个元素必须相同。
下边两个图是两个Buffer在比较时相同的情况(深色部分是比较区域),两个对象调用equals会得到true:
而下边两个图则是Buffer在比较时不同的情况:
本文主要讲解数据结构,您理解了java.nio.Buffer的原理过后,回头来理解Vert.x中的缓冲区就变得简单了,大道通天,不论什么语言、什么操作系统、什么平台,在原理层几乎都是相同或者近似的,所以从概念上去理解一个数据结构比单纯当做工具来使用要重要很多。接下来看看Vert.x中的Buffer,并且可以比较一下和Java 8中的Buffer的差异。
2. Netty中的Buffer
很多您会很奇怪,我们明明学习的是Vert.x,为什么要理解Netty中的Buffer呢?——Vert.x的底层就是对Netty中的Buffer进行的封装,主要抽象类使用的是io.netty.buffer.ByteBuf。Netty框架本身并没有直接使用Java NIO的Buffer实现,而是自己实现了一套Buffer框架来满足业务或者性能需求。
2.1. 再谈Buffer
前文已经提到过Buffer的中文名叫缓冲区,如果在线搜索,您可以搜索到它的基本定义:在数据传输时,在内存里开辟的一块临时保存数据的区域。——其实它解决的是数据传输过程两端的IO设备传输速率不稳定或不对等的问题。最早版本的Java IO编程中,我们通常会说Java语言里会被IO的读取分成字符流和字节流,不论使用哪种数据流,在真正读写过程,都存在使用Buffer来实现中间的缓冲过程,相信这两个方法的调用很多人都不陌生:write()和flush()以及最终执行完成后的close()。
第一章节中的java.nio实际上就是把这个概念封装成了更容易操作的对象,如flip()或compact()等,其实在编程过程中,如果您不需要关心数组的索引,而只是纯粹用集合的方式来操作,那么编程会变得相对简单。那么Netty中的Buffer和Java语言原生的区别在哪儿呢?Netty中的Buffer是为了网络通讯而生,配合前文提到的通道(Channel),它更像是一种特殊用途的Buffer,而在纯异步网络IO中(AIO),Buffer起了同步转异步的粘合剂的作用。
再强调一次,Vert.x中的
io.vertx.core.buffer.Buffer的默认底层实现使用的是Netty中的Buffer,如果理解了Netty中Buffer的原理,那么再理解Vert.x中的Buffer就简单许多了。
2.2. TCP/IP与Buffer
TCP/IP协议是目前主流的网络传输协议,由于网络协议底层复杂,对编程人员而言没有必要在开发过程中深入那么复杂的内部原理(能理解透彻当然更好),所以开发过程中我们会面向套接字(Socket)编程。套接字(Socket)是编程中的一个抽象层,应用程序只要通过它就可以发送和接收数据,而操作就像打开、读写、关闭文件一样简单。
套接字的内核存在一个发送缓冲区和接收缓冲区,TCP中的全双工工作模式和TCP的流量控制就是依赖这两个独立的Buffer和Buffer的填充状态来实现。
接收缓冲区把数据存储到内核中,如果应用程序一直没有调用recv()(接收)读取的话,该数据会一直存在于接收缓冲区——任何对端发过来的数据都会经过该缓冲区,recv()方法会把内核缓冲区的数据拷贝到应用程的Buffer中(通常编程中的缓冲区对象)。
如果某个进程调用send()(发送)写数据,会把数据拷贝到套接字内核的发送缓冲区,然后该操作被封装成句柄在上层返回,返回的时候数据还没发送到对端去,这个和Java中常用的write方法类似——它只是把数据拷贝到了内核中的发送缓冲区,它会等着TCP来触发“发送”的动作。
TCP发送数据都是以报文的形式发送,它的报文有个必将大的特点就是传输的时候会把应用数据拆分成字节,并且以数据帧(Frame)的方式传播,传播时会根据自己的需要执行。TCP本身具有最大长度限制,数据量过大的时候就必须执行拆分。而且TCP下层协议在传输的时候,每个报文都会追加一个报头信息,而数据量小的话,这些报头就失去了意义(报头通常是描述数据本身用的),这种情况下,传输就会特别不划算,所以除了最大限制以外,还会有最小数据限制。参考1下图:
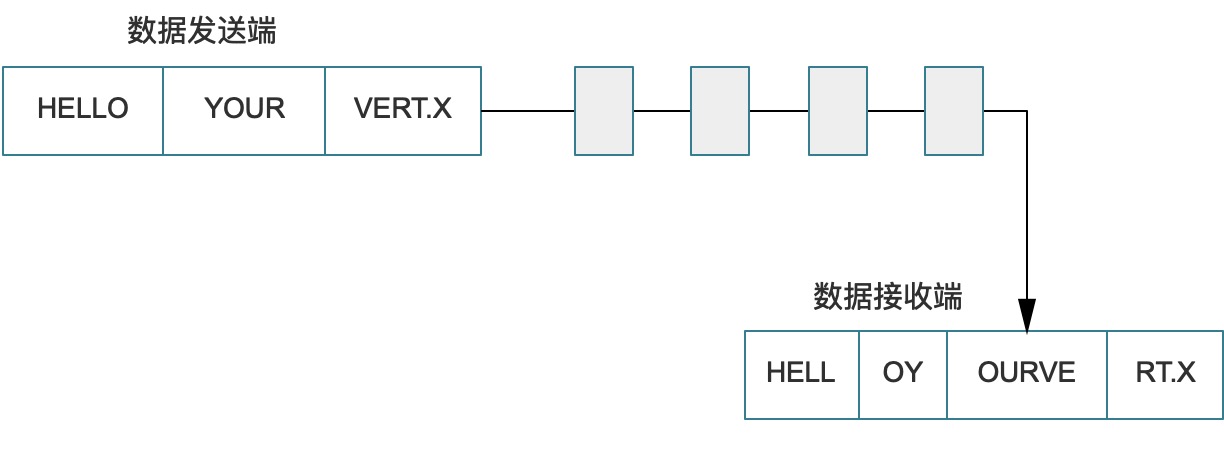
本文不介绍TCP/IP的协议,您有兴趣可以去阅读相关资料。
Netty中的Buffer还有一个特点是,它不是一个包packet的队列,而是字节队列,如上图演示的,若您发送了三个消息(HELLO, YOUR, VERT.X),即使这三个消息是以三个独立的包packet发送的,而Netty在处理时会把它当做一堆字节处理,所以才会出现接受端看到的是一堆字节,而这些字节构造的最终消息片段可能不完整,但整体消息是完整的。简单说,是分段将HELLO YOUR VERT.X发送过来还是一次性发送过来的最终数据是一致的。
2.3. ByteBuf初探
Netty 3.x 之前的版本使用的是
ChannelBuffer类,而 4.x 之后 Netty 中定义的缓冲区使用了独立的类:io.netty.buffer.ByteBuf(Vert.x内部也使用了这个类)。
若您仔细阅读过前一个章节,相信对Java NIO中提到的Buffer已经有所了解,Netty中的ByteBuf就是它内部缓冲区的抽象接口定义,参考源码中这段注释:
/** ......
* It is recommended to create a new buffer using the helper methods in
* {@link Unpooled} rather than calling an individual implementation's
* constructor. ......
**/
Vert.x中的Buffer实现类io.vertx.core.buffer.impl.BufferImpl中创建ByteBuf代码如:
BufferImpl(int initialSizeHint) {
buffer = Unpooled.unreleasableBuffer(Unpooled.buffer(initialSizeHint,
Integer.MAX_VALUE));
}
BufferImpl(byte[] bytes) {
buffer = Unpooled.unreleasableBuffer(Unpooled.buffer(bytes.length,
Integer.MAX_VALUE)).writeBytes(bytes);
}
ByteBuf类提供的API虽然很多,但屏蔽了一系列的缓冲区操作复杂度,它和Java NIO中提到的缓冲区的优势如下:
- 用户可以自己定义缓冲区类型进行扩展。
- 内置了复合缓冲区类型实现了透明零拷贝。
- 容量可以随着需求的递增而扩大(类似JDK中
StringBuffer/StringBuilder)。 - 读就绪和写就绪两种模式之间切换时不需要调用
flip。 - 读和写使用不同的索引。
- 支持方法的链式调用(@Fluent模式)。
- 支持引用计数器。
- 池化管理。
ByteBuf的读写索引分离,它维护了不同的读索引和写索引,这两个索引将整个缓冲区划分成了三份,如下图:

任何新分配的、包装的、复制的缓冲区的默认大小中读写索引值都是0,任何readX或skipX类的API操作都会增加读索引(readerIndex)的已读字节,而writeX类的API操作都会增加写索引(writerIndex)相对应的字节数。下图呈现了一个空的ByteBuf的内部结构:
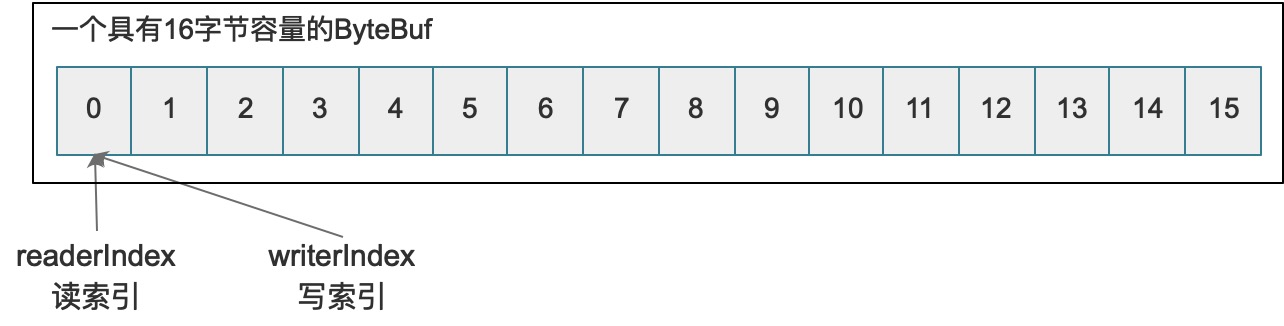
若要读取缓冲区中数据,readerIndex和writerIndex相同时,就表示不能再继续读取数据了,这种情况下会抛出IndexOutOfBoundsException的异常。在前文中,Java NIO中使用了position, mark, limit的位置切换来执行读写切换,而在ByteBuf的实现中,直接将读写进行了分离,io.netty.buffer.AbstractByteBuf中有下边的变量定义:
int readerIndex; // 读索引
int writerIndex; // 写索引
private int markedReaderIndex; // 标记读索引
private int markedWriterIndex; // 标记写索引
private int maxCapacity; // 缓冲区的最大容量
有了这五个变量,在缓冲区的读写中就不需要limit属性了,逻辑上更加清晰,它们之间操作区域对比如下:
| 操作类型 | 起点索引 | 结束索引 |
|---|---|---|
| NIO 读 | mark / position | limit |
| NIO 写 | position | limit / capacity |
| ByteBuf 读 | markedReaderIndex / readerIndex | writerIndex |
| ByteBuf 写 | markedWriterIndex / writerIndex | maxCapacity |
从对比表格可以看到ByteBuf与JDK中的ByteBuffer的最大区别在于:
- Netty中的ByteBuf采用读写分离,一个初始化的ByteBuf的读写索引都是
0,读写的切换不需要使用NIO中的flip操作。 - 若读索引和写索引处于同一个位置,若继续读取就会抛出
IndexOutOfBoundsException异常。 - ByteBuf的任何读写操作都会单独分离到
readerIndex和writerIndex中,maxCapacity最大容量的默认值限制是Integer.MAX_VALUE。
2.4. 模式对比
Java NIO模式
Java NIO中的缓冲区模式主要包含两种:直接模式(Direct Buffer)和堆模式(Heap Buffer),直接模式使用DirectByteBuffer实现类,而堆模式就是使用的前文提到的ByteBuffer实现类,二者最大的区别在于缓冲区内存管理的方式。ByteBuffer使用的是堆内存,如前文打印结果中可看到的:
java.nio.HeapByteBuffer[pos=5 lim=10 cap=10]
DirectByteBuffer使用的是堆外的内存(直接内存),堆外内存的优点就是在执行任何IO操作时数据拷贝的次数相对少、而性能非常高。但是由于内存管理中,不论堆外还是堆内都会引入一系列和内存分配/回收相关的问题,所以两种内存各有优劣。 ByteBuffer在真实使用过程中暴露出一定的问题:对IO操作而言,拷贝字节数组的次数越少,IO性能也就越高。ByteBuffer的性能地下的几个原因如下2:
- 将堆内存中的缓冲区数据拷贝到临时缓冲区。
- 对临时缓冲区的数据执行低层读写。
- 临时缓冲区对象离开作用域,并最终被回收成无用数据。
对应的,DirectByteBuffer直接将内存分配在了堆外内存,因此可直接执行低层读写,减少了拷贝次数,也提高了性能。实际上直接内存采用了内存引用法则,参考Java内存模型3,本质上DirectByteBuffer对象是存储在堆内的,而它保存了一个内存引用(一个地址),这个地址指向堆外的内存块,这个内存块是不受Java虚拟机管理的,在这种情况下,内存回收就变得很重要了。参考下图4:
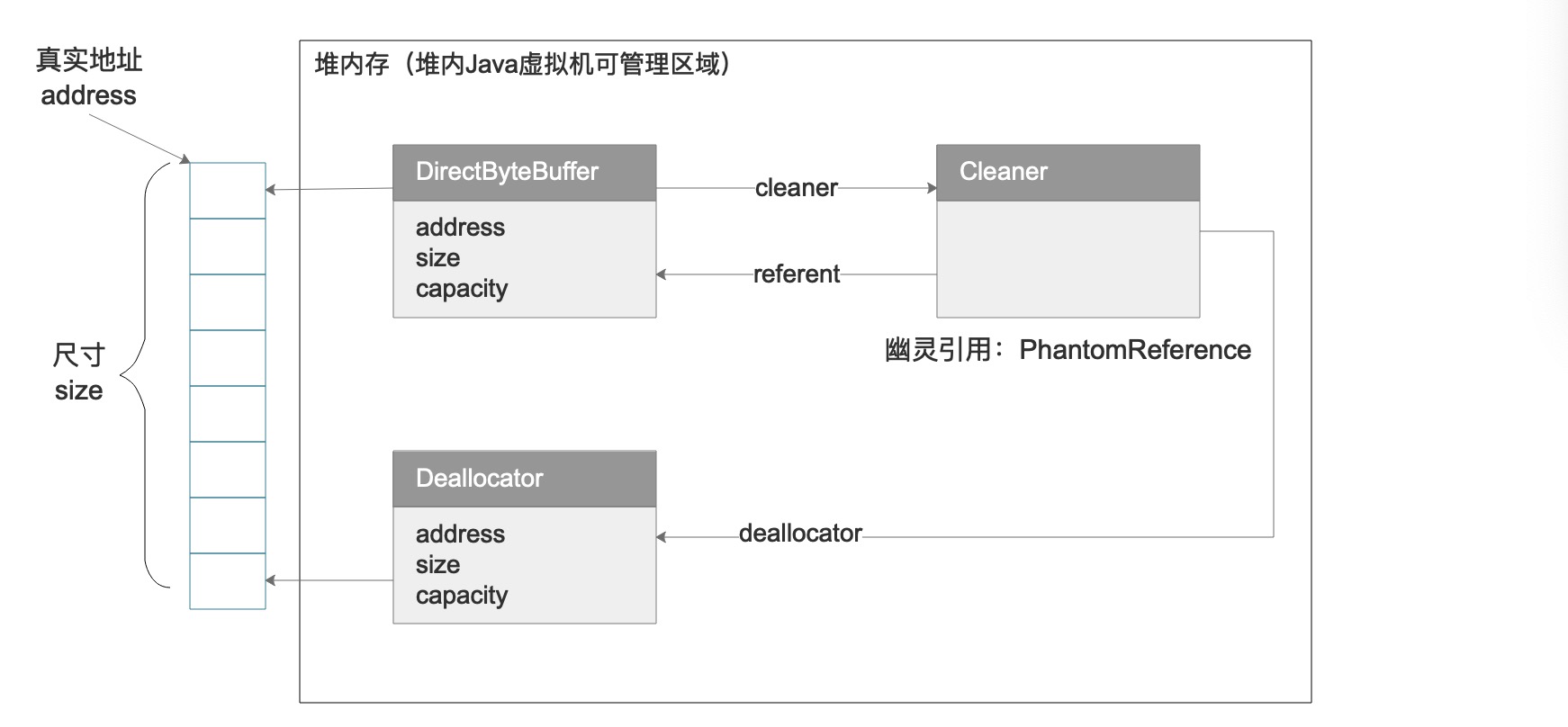
参考它的源代码,
unsafe.allocateMemory(size)的操作就是上边提到低层操作,它使用了Java中的native关键字,会通过JNI(Java Native Interface)调用操作系统本地接口,直接进行堆外内存分配。
在DirectByteBuffer被创建时,它会创建一个继承于PhantomReference的Cleaner对象,该对象是一个虚引用(又称为“幽灵引用”),它被放到一个等待队列中,然后等待另一个线程去处理这个队列并执行内存回收。由于该内存不受JVM管理,所以需要回收时只能调用clean()方法执行堆外内存释放,——根据垃圾回收器的执行原理,API调用过后,内存并不会真正释放,而是等待操作系统调度来执行内存回收,这个过程中如果出现了响应不及时(线程优先级低、IO设备问题),内存回收就会引起问题。综上,DirectByteBuffer性能很高,如果您要使用它,最好手动控制它的垃圾回收以保证使用过程不会引起额外的内存问题。
ByteBuf的模式
ByteBuf本质上是一个分配了双索引的字节数组,它有三种模式:堆模式(Heap Buffer)、直接模式(Direct Buffer)和复合模式(Composite),前边两种模式和NIO部分的两种模式区别不大,而ByteBuf中引入了一种新的模式:复合模式。先看下表对比一下几种模式的优劣:
| 模式 | 描述 | 优点 | 缺点 |
|---|---|---|---|
| 堆模式 | 存储于JVM内存空间,支撑数组(Backing Array) | 若不使用池化情况可提供快速分配和释放 | 发送之前多一层拷贝,拷贝到临时缓冲区 |
| 直接模式 | 存储在物理内存中 | 能获取超过JVM堆限制的容量,性能更强 | 释放和分配空间昂贵,操作时需一次性复制 |
| 复合模式 | 单个缓冲区合并多个缓冲区 | 操作多个更方便 | (升级版) |
在Netty中使用CompositeByteBuf实现复合模式,复合模式为多个ByteBuf提供了一个聚合视图,这里可以根据实际场景所需添加或删除ByteBuf——这个特性就是NIO中没有的。Netty中使用该模式优化了套接字的IO操作,尽可能消除JDK缓冲区实现导致的性能和内存使用率的影响。
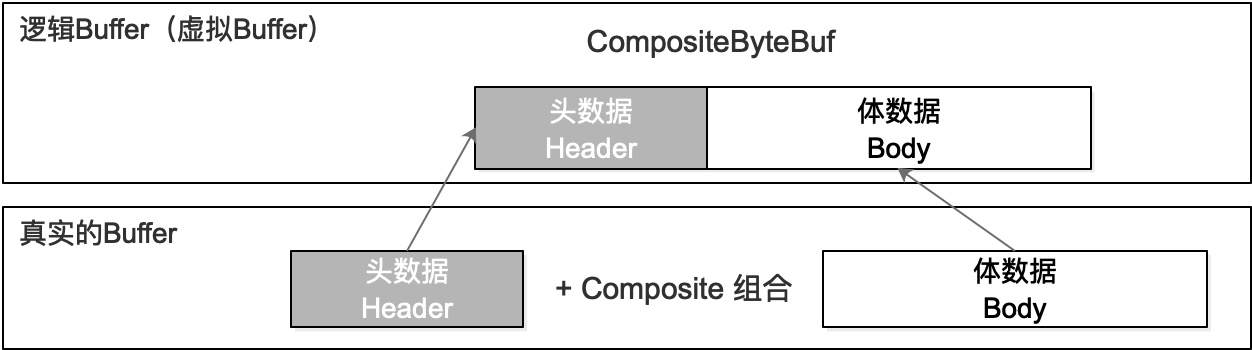
您需要注意CompositeByteBuf是由两个或两个以上的ByteBuf组合而成(如上图),而它的内部,这些ByteBuf都是单独存在的,它只是一个逻辑上的整体,真实的结构就是使用的ByteBuf集合,内置定义如下:
// ......
// 实例定义的存储结构是一个 Component 数组
private Component[] components; // resized when needed
// ......
// 内部类中,每个 Component 包含了两个 ByteBuf
private static final class Component {
final ByteBuf srcBuf; // the originally added buffer
final ByteBuf buf; // srcBuf unwrapped zero or more times
// ......
}
// ......
Netty中的CompositeByteBuf还实现了零拷贝(Zero-copy):
"Zero-copy" describes computer operations in which the CPU does not perform the task of copying data from one memory area to another. This is frequently used to save CPU cycles and memory bandwidth when transmitting a file over a network.
如果直接使用NIO中的ByteBuffer,它会将堆内缓冲区数据拷贝到临时缓冲区中。零拷贝——操作数据时,不需要讲缓冲区数据从一个内存区域拷贝到另外一个内存区域,减少一次内存拷贝而提高CPU效率的技术。
从操作系统层面讲,零拷贝表示在用户态(User)和内核态(Kernel)之前切换时避免数据来回拷贝。如mmap操作(内存映射文件),该操作调用使得两个进程之间共享一个文件来实现内存共享,进程访问内存数据如同访问文件一样,而针对数据的读写都会直接反映到文件变更上,当用户态和内核态切换时,就不需要执行数据拷贝了,如此就提高了执行效率。
Netty中的零拷贝和操作系统中的零拷贝有些区别,首先Netty是一个运行在JVM上的Java应用,它只能运行了用户态,它的零拷贝不是两态的切换,而是优化数据效率。
- CompositeByteBuf中本身就组合了多个ByteBuf,逻辑上它可以合并成一个ByteBuf,避免各个ByteBuf之间的拷贝。
- 它使用了wrap操作,将byte[]数组、ByteBuf、ByteBuffer包装成了一个 Netty 中的 ByteBuf 对象,避免拷贝操作。
- ByteBuf支持 slice 操作,可以将 ByteBuf 分解成多个共享同一存储空间的 ByteBuf,避免了内存上的拷贝。
- 最后,它通过
FileRegion包装的FileChannel.transferTo实现文件传输,将文件缓冲区数据发送到目标通道(Channel),避免了传统的循环方式导致内存拷贝问题。
2.5. ByteBuf字节级操作
ByteBuf有两种核心访问方式:
- 随机访问:
setX, getX类的相关方法,不修改索引。 - 顺序方法:
readX, writeX开头的方法,根据已经访问的字节对索引进行调整,这个索引就是前文提到的读索引和写索引。
随机访问
参考下边代码:
package io.vertx.up._02.buffer;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
public class NBufferGet {
public static void main(final String[] args) {
// 初始化
final ByteBuf buf = Unpooled.buffer(16);
for (int i = 0; i < 16; i++) {
buf.setByte(i, i);
}
System.out.print(buf.getByte(5) + ", ");
System.out.println(buf.readerIndex() + ", " + buf.writerIndex());
// 输出: 5, 0, 0
}
}
上边代码执行过后,最终存储结构如下:
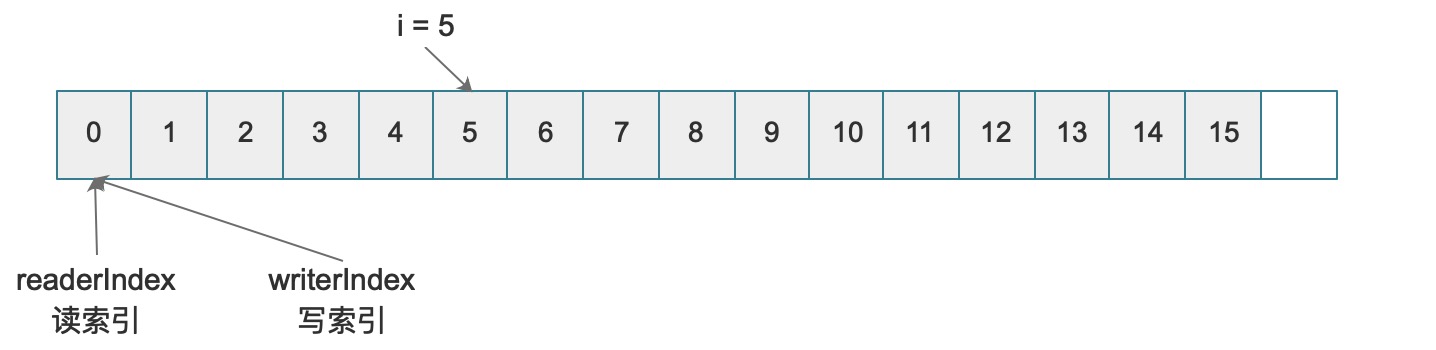
简单说,getByte/writeByte以及类似的方法在访问byte时并不会改变读索引和写索引的位置,如果要改变读写索引的位置,则需要调用另外的方法。
顺序访问
再看一段代码,理解一下顺序访问:
package io.vertx.up._02.buffer;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
public class NBufferIndex {
public static void main(final String[] args) {
// 初始化
final ByteBuf buf = Unpooled.buffer(16);
for (int i = 0; i < 16; i++) {
buf.writeByte(i);
}
final ByteBuf result = buf.readBytes(5);
System.out.println(result);
for (int idx = 0; idx < 5; idx++) {
System.out.print(result.getByte(idx) + ",");
}
System.out.println();
System.out.println(result);
System.out.println(buf.readerIndex() + ", " + buf.writerIndex());
}
}
上边代码执行后会输出:
# 这里只关心内容,所以就不提供类型部分的输出信息
...DirectByteBuf(ridx: 0, widx: 5, cap: 5)
0,1,2,3,4,
...DirectByteBuf(ridx: 0, widx: 5, cap: 5)
5, 16
最终结构如下:
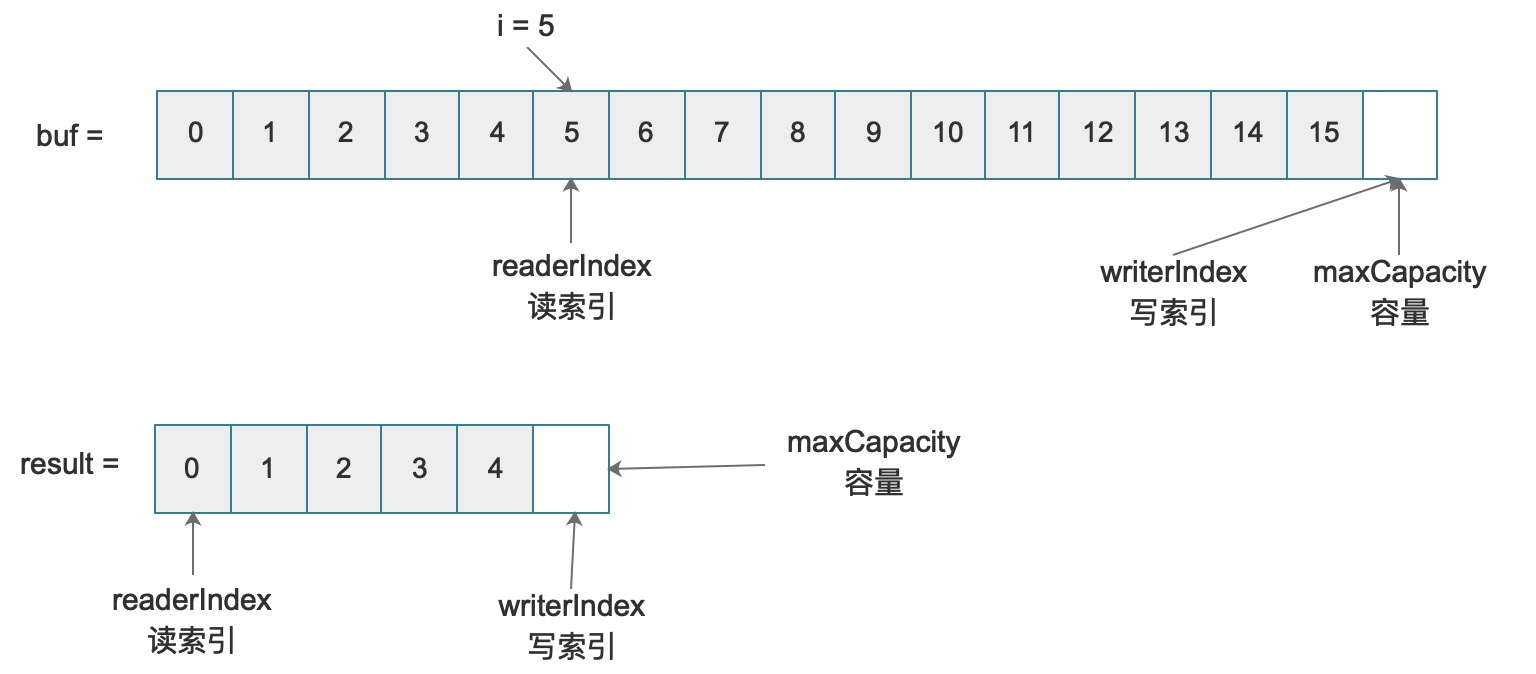
这里可以知道,所有的writeX/readX类的方法,不仅仅可以读写缓冲区,还会改变缓冲区中的读索引和写索引信息,细心的您会发现,readX类的方法返回值主要分为两大类,如果它的返回值是ByteBuf类型,那么它会按照传入参数创建一个新的ByteBuf,这就是上边为什么有两个结构的原因。底层调用如:
ByteBuf buf = alloc().buffer(length, maxCapacity);
buf.writeBytes(this, readerIndex, length);
缓冲区重用
当读索引被移动过后,如果要重新读取该缓冲区的数据,应该如何操作呢?此时就需要使用到discardReadBytes()方法,这个方法在网上众说纷纭,很多开发人员也遇到了不少坑。首先,还是看一段代码:
package io.vertx.up._02.buffer;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
public class NBufferDiscard {
public static void main(final String[] args) {
// 初始化
final ByteBuf buf = Unpooled.buffer(16);
for (int i = 0; i < 16; i++) {
buf.writeByte(i);
}
final ByteBuf sub = buf.readBytes(7);
System.out.println("Buffer, " + buf);
final ByteBuf created = buf.discardReadBytes();
System.out.println("Buffer, " + buf);
System.out.println("Sub, " + sub);
System.out.println("Discard, " + created);
}
}
上述代码的输出如下:
Buffer, ...HeapByteBuf(ridx: 7, widx: 16, cap: 16)
Buffer, ...HeapByteBuf(ridx: 0, widx: 9, cap: 16)
Sub, ...DirectByteBuf(ridx: 0, widx: 7, cap: 7)
Discard, ...HeapByteBuf(ridx: 0, widx: 9, cap: 16)
返回的两个新的
ByteBuf可以理解成创建了执行过后的结果,
代码执行后,原始的缓冲区变化如下:
 发现问题了吗?调用了
发现问题了吗?调用了discardReadBytes过后,原始的三个区域已经发生了改变,可丢弃的字节区域就真正被丢弃了,而可读区域直接在原始缓冲区中执行了平移,可写区域就成了剩下的区域,进行了扩展。细心的您会发现,这个操作就类似于NIO中的compact动作,对的,除了读写索引的平移以外,原始的ByteBuf索引(0 ~ 8)的部分被原始可读区域的内容覆盖了。那么,这个ByteBuf就可以被重新读写了,也就是本小节提到的重用。
ByteBuf的思考
上边我们使用了很多例子来操作ByteBuf,但很多方法都是直接返回了ByteBuf,既然返回了这个类型,我们需要思考:究竟这个方法是创建了一个新的ByteBuf还是返回原始的ByteBuf?为什么这个问题很重要,创建一个新的ByteBuf是需要在底层重新分配内存存储空间,而返回的是原始引用,则不需要执行该操作,性能要好很多。
参考下边代码:
package io.vertx.up._02.buffer;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
public class NBufferConsider {
public static void main(final String[] args) {
{
// discard
final ByteBuf buf = create();
System.out.println("Buffer, " +
buf.hashCode() + ", " + buf);
final ByteBuf discard = buf.discardReadBytes();
System.out.println("Discard, " +
discard.hashCode() + ", " + discard);
System.out.println(buf == discard);
}
{
// read
final ByteBuf buf = create();
System.out.println("Buffer, " +
buf.hashCode() + ", " + buf);
final ByteBuf sub = buf.readBytes(4);
System.out.println("Sub, " +
sub.hashCode() + ", " + sub);
System.out.println(buf == sub);
}
{
// slice
final ByteBuf buf = create();
System.out.println("Buffer, " +
buf.hashCode() + ", " + buf);
final ByteBuf slice = buf.slice(3, 8);
System.out.println("Slice, " +
slice.hashCode() + ", " + slice);
System.out.println(buf == slice);
}
{
// duplicated
final ByteBuf buf = create();
System.out.println("Buffer, " +
buf.hashCode() + ", " + buf);
final ByteBuf duplicated = buf.duplicate();
System.out.println("Duplicated, " +
duplicated.hashCode() + ", " + duplicated);
System.out.println(buf == duplicated);
}
}
private static ByteBuf create() {
// 初始化
final ByteBuf buf = Unpooled.buffer(16);
for (int i = 0; i < 16; i++) {
buf.writeByte(i);
}
buf.readBytes(7);
return buf;
}
}
运行上述代码,可以看到如下输出:
Buffer, -1147144278, ...HeapByteBuf(ridx: 7, widx: 16, cap: 16)
Discard, -1147144278, ...HeapByteBuf(ridx: 0, widx: 9, cap: 16)
true
Buffer, -1147144278, ...HeapByteBuf(ridx: 7, widx: 16, cap: 16)
Sub, 117967145, ...DirectByteBuf(ridx: 0, widx: 4, cap: 4)
false
Buffer, -1147144278, ...HeapByteBuf(ridx: 7, widx: 16, cap: 16)
Slice, 1686415493, ...SlicedByteBuf(ridx: 0, widx: 8, cap: 8/8, \
unwrapped: ...UnsafeHeapByteBuf(ridx: 7, widx: 16, cap: 16))
false
Buffer, -1147144278, ...HeapByteBuf(ridx: 7, widx: 16, cap: 16)
Duplicated, -1147144278, ...DuplicatedByteBuf(ridx: 7, widx: 16, cap: 16, \
unwrapped: ...HeapByteBuf(ridx: 7, widx: 16, cap: 16))
false
为了保证每个操作的原子起点是一致的,所以全部放到“块代码”中执行每个原子操作,输出的时候使用 == 比较就是检查当前对象是是否已经发生了改变。
仔细分析上述代码的执行结果:
- 执行了
discardReadBytes()过后,直接修改了当前缓冲区的内容,并且移动了索引,但是返回的时候并不会重新创建新的ByteBuf。 - 执行
readBytes类似的方法返回ByteBuf时,实际上是返回的一个新的实例,而不是原始实例。 - 执行了
slice和duplicate操作过后,不仅返回了一个新的实例,而且内部存储了原始缓冲区的引用。 - 注意最后一点,
duplicate操作过后的ByteBuf对象虽然返回了相同的hashCode,但是它们依旧没有指向同一个对象,属于两个不同的对象。
其实ByteBuf中的这些操作和String/StringBuilder中的操作类似,如slice, duplicate, readBytes类的方法返回时,都是创建了一个新的ByteBuf,近似于String的不可变特性;而discardReadBytes调用之后只是修改了内容和平移索引,近似于StringBuilder的可变特性。
读到这里,相信您对Java NIO和Netty ByteBuf的核心原理都有了更深入的了解,关于其他内容您可以去查阅相关源代码进行更加深入的理解和求证。有了这些知识作基础,回头来学习Vert.x中的Buffer就简单很多了。
3. Vert.x中的Buffer
在官方网站上有这样一句话:
A buffer is a sequence of zero or more bytes that can read from or written to and which expands automatically as necessary to accommodate any bytes written to it. You can perhaps think of a buffer as smart byte array.
3.1. 基本操作
创建
在编程过程中,创建Buffer的过程很简单,跟着官方文档带您看一份概念代码:
package io.vertx.up._02.buffer;
import io.netty.buffer.ByteBuf;
import io.netty.buffer.Unpooled;
import io.vertx.core.buffer.Buffer;
public class VBufferFirst {
public static void main(final String[] args) {
// 创建默认的Buffer(无内容)
final Buffer buffer = Buffer.buffer();
System.out.println(buffer.toString() + "," + buffer.length());
// 字节数组创建
final String helloWorld = "Hello World";
final Buffer byteBuf = Buffer.buffer(helloWorld.getBytes());
System.out.println(byteBuf.toString() + "," + byteBuf.length());
// 字符串创建
final Buffer strBuf = Buffer.buffer(helloWorld);
System.out.println(strBuf.toString() + "," + strBuf.length());
// 带编码的字符串创建
final Buffer strEBuf = Buffer.buffer(helloWorld, "utf-8");
System.out.println(strEBuf.toString() + "," + strEBuf.length());
// 直接使用 ByteBuf
final ByteBuf buf = Unpooled.buffer(16);
for (int i = 0; i < 16; i++) {
buf.writeByte(i);
}
final Buffer defaultBuf = Buffer.buffer(buf);
System.out.println(defaultBuf.toString() + "," + defaultBuf.length());
// 直接初始化带尺寸的
final Buffer sizeBuf = Buffer.buffer(20);
System.out.println(sizeBuf.toString() + "," + sizeBuf.length());
}
}
上述代码的输出如下:

可能您会困惑,上边代码中最后一个Buffer的长度指定的是20,为什么会返回0呢?——因为Vert.x中的Buffer计算长度时,底层返回的是ByteBuf的写索引writerIndex而不是容量,最后一行代码的实参20指定的是maxCapacity的值。
若您对
writerIndex仍有疑惑,可以回顾本章第二节部分的内容,这里不重复。
写入/随机访问
Buffer的写入方法在Vert.x中直接使用appendX的方法来实现,看一段简单的代码:
package io.vertx.up._02.buffer;
import io.vertx.core.buffer.Buffer;
public class VBufferWrite {
// 官方例子
public static void main(final String[] args) {
final Buffer buff = Buffer.buffer();
buff.appendInt(123).appendString("hello\n");
System.out.println(buff.toString());
}
}
在写入缓冲区方法有一点需要注意:appendX方法会改变底层ByteBuf的写索引(writeIndex),它调用的方法是ByteBuf中的writeX类的方法,而不是putX方法,这种情况下,Buffer的底层写索引会发生改变,按照上一节最后的总结,如果appendX过后写索引发生了改变,那么length()的返回值就发生了变化,也符合逻辑。
再看一段代码,理解一下索引访问(通常也称为随机访问):
package io.vertx.up._02.buffer;
import io.vertx.core.buffer.Buffer;
public class VBufferSet {
public static void main(final String[] args) {
final Buffer buff = Buffer.buffer();
buff.appendString("hello\n");
buff.setString(3, "X");
System.out.println(buff.toString() + ", " + buff.length());
buff.setString(8, "X");
System.out.println(buff.toString() + ", " + buff.length());
}
}
上述代码很容易理解,先用Hello构造一个Buffer,然后修改掉索引位置为3的字符,然后设置索引位置为8的字符,它的输出如下(注意\n的换行符):

您需要小心一点的是,Vert.x中的索引访问和第二节中提到的ByteBuf的索引访问是有区别的,ByteBuf中的setX类的索引访问在处理过程中不改变任何底层的索引位置(包括读索引和写索引),而Vert.x中的Buffer底层执行了智能扩容的操作:
int ni = pos + len;
int cap = buffer.capacity();
int over = ni - cap;
if (over > 0) {
buffer.writerIndex(cap);
buffer.ensureWritable(over);
}
// We have to make sure that the writerindex is
// always positioned on the last bit of data set in the buffer
if (ni > buffer.writerIndex()) {
buffer.writerIndex(ni);
}
有了这种操作后,它的随机访问就演变成了一个有副作用的版本:
setX类方法调用过后,它更改了底层ByteBuf的写索引。- 直接对底层的ByteBuf进行扩容操作,在
Integer.MAX_VALUE范围之内不会抛出异常。
上述结论是和ByteBuf中的索引访问最大的差异,ByteBuf中的 set 方法不会改变任何索引的位置,而Vert.x中的Buffer的setX/appendX都会更改底层的写索引以配合length()在逻辑上的输出信息——这也是Vert.x中的Buffer比较智能的特性之一。
读写顺序
读写顺序是Buffer中的一个容易出错的地方,先看下边代码:
package io.vertx.up._02.buffer;
import io.vertx.core.buffer.Buffer;
public class VBufferSeq {
public static void main(final String[] args) {
/*
* 插入处理
*/
final Buffer buffer = Buffer.buffer();
buffer.appendDouble(12.5);
buffer.appendString("Hello");
buffer.appendInt(33);
/*
* 读取数据
*/
System.out.println(buffer.getDouble(0));
System.out.println(buffer.getString(8, 13));
System.out.println(buffer.getInt(13));
}
}
上边代码执行过后输出符合我们的预期:
12.5
Hello
33
这里的索引0、8、13和写入时的数据类型有关,上边代码写入的顺序是:double -> String -> int,那么当前的Buffer中的存储结构如下:
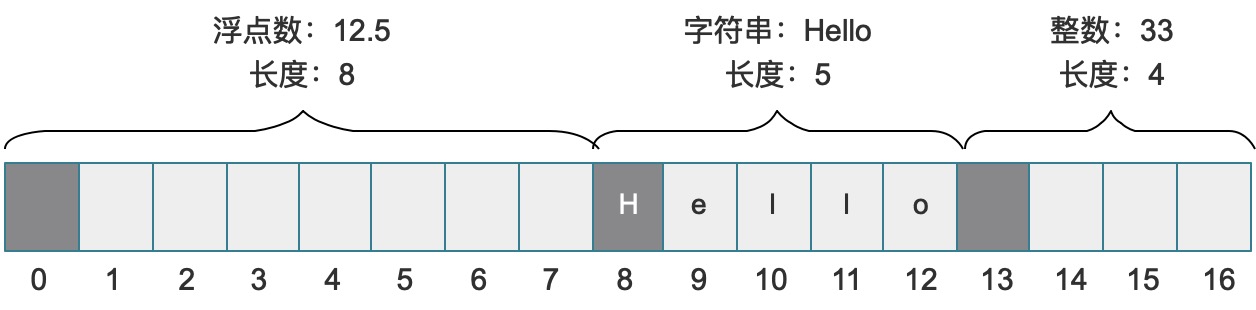
深色区域就是代码中值的来源,而不同的数据类型长度不同,所以这种操作要求您对Java基础类型的长度十分了解,参考下边表格:
| 类型 | 长度 |
|---|---|
| boolean | 不支持 |
| byte | 1 |
| char | 2 |
| short | 2 |
| int | 4 |
| long | 8 |
| float | 4 |
| double | 8 |
| String | length() |
最后提供一个概念例子,您可以自己去分析以加深对Buffer的理解。
package io.vertx.up._02.buffer;
import io.vertx.core.buffer.Buffer;
public class VBufferSeq1 {
public static void main(final String[] args) {
/*
* 插入处理
*/
final Buffer buffer = Buffer.buffer();
buffer.appendDouble(12.5);
buffer.appendString("Hello");
buffer.appendInt(33);
buffer.appendByte((byte) 8);
final float floatValue = 12.2f;
buffer.appendFloat(floatValue);
buffer.appendIntLE(6);
buffer.appendString("end");
/*
* 读取数据
*/
System.out.println(buffer.getDouble(0));
System.out.println(buffer.getString(8, 13));
System.out.println(buffer.getInt(13));
System.out.println(buffer.getByte(17));
System.out.println(buffer.getFloat(18));
System.out.println(buffer.getFloat(22));
System.out.println(buffer.getString(26, 29));
}
}
这个例子就留给您自己去分析了,最后还提供一个技巧,细心的您会发现在Vert.x中的Buffer使用时,提供了类似下边的方法:
- appendIntLE(int)
- appendMedium(int)
- appendUnsignedByte(short)
- appendUnsignedIntLE(long)
您可以不用去纠结这些方法在读取时的长度操作,将这些方法的形参类型和上边提供的表结构进行比对,就可以知道您append到缓冲区的数据实际长度是多少了,这样理解起来会变更更加简单。
使用小结
本小节对Vert.x中的Buffer用法做个小结,由于getX类的方法以及slice/copy这些在官方文档中有介绍,而且理解了前两章的内容后,就很容易理解它具体做了些什么,所以我们只一起看看容易被忽略的小细节,帮助您完善开发的知识体系。
- Buffer中的
length()方法返回的是底层ByteBuf的写索引(writerIndex)。 - Buffer中的索引访问使用方法会智能操作,除了设置索引位置的值,还会自动扩容并且更改Buffer中的写索引。
- Buffer写入到了Socket或类似地方,那么这个Buffer就会直接被消费,不可重用。
- 写入Buffer的数据顺序和读取Buffer的数据顺序必须一致,并且要求计算每种数据类型的长度才能精确读取到期望的数据。
接下来的章节我们看几个比较复杂的实战案例。
3.2. 实战分析
实现ClusterSerializable接口
用户类有三个属性:id, username, password,由于它实现了io.vertx.core.shareddata.impl.ClusterSerializable接口,所以必须提供两个核心方法的序列化/反序列化的操作。
Buffalo工具类
package io.vertx.up._02.buffer.cases;
import io.vertx.core.buffer.Buffer;
import io.vertx.up.eon.Values;
import io.vertx.up.util.Ut;
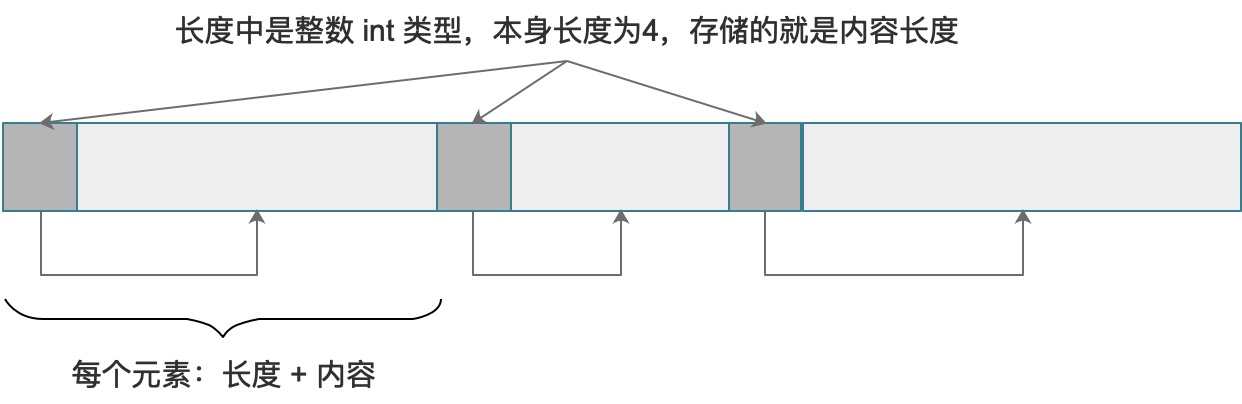
public class Buffalo {
public static void write(final Buffer buffer,
final String... data) {
// 遍历数据
for (final String item : data) {
if (Ut.isNil(item)) {
// 字节数据
final byte[] bytes = item.getBytes(Values.DEFAULT_CHARSET);
buffer.appendInt(bytes.length);
buffer.appendBytes(bytes);
}
}
}
public static int read(final int start,
final Buffer buffer,
final String[] reference) {
int pos = start;
for (int idx = 0; idx < reference.length; idx++) {
// 先读取长度信息
final int len = buffer.getInt(pos);
// 计算偏移量
pos += 4;
// 读取本身内容
final byte[] bytes = buffer.getBytes(pos, pos + len);
reference[idx] = new String(bytes, Values.DEFAULT_CHARSET);
pos += len;
}
return pos;
}
}
用户类
package io.vertx.up._02.buffer.cases;
import io.vertx.core.buffer.Buffer;
import io.vertx.core.shareddata.impl.ClusterSerializable;
public class BasicUser implements ClusterSerializable {
private transient String id;
private transient String username;
private transient String password;
@Override
public void writeToBuffer(final Buffer buffer) {
/* 写入id,用户名和token **/
Buffalo.write(buffer, this.id, this.username, this.password);
}
@Override
public int readFromBuffer(int pos, final Buffer buffer) {
/* 读取信息 **/
final String[] reference = new String[3];
pos = Buffalo.read(pos, buffer, reference);
/* 从引用中读取数据 **/
this.id = reference[0];
this.username = reference[1];
this.password = reference[2];
return pos;
}
}
上述代码是Vert.x中某个Pojo实现接口ClusterSerializable的常用代码,有几点需要注意:
- 在工具类的
write/read两个方法中我们使用的形参都是数组,主要原因是数组是有序的,这样的话在写入和读取时可以保持唯一的顺序。 - 在写入数据的过程中,除了写入数据内容以外,会把该数据的长度以
int类型写入到数据段的头部中,那么这样就可以直接从Buffer中读取当前数据段的长度信息。 readFromBuffer的返回值就是最终读取过后的偏移量。
上边代码和前一小节中的直接appendX的结构有所区别,参考下图(深色部分是存储内容长度的存储空间):
4. 总结
本章主要讲解了Vert.x中的io.vertx.core.buffer.Buffer的原理和用法,通过对Java NIO中的Buffer原理分析和Netty中ByteBuf的原理分析,让您对Buffer这种数据结构有更深入的了解,Vert.x中的Buffer并没有重写整套体系,而是直接使用了Netty中的ByteBuf,而Netty中的ByteBuf和Java NIO中的Buffer不是同一个家族的结构。但是——从原理分析可以知道,二者实现的目标和原理是一致的,只是在细微的概念层有所区别。
在编程中,开发人员可以根据自己的实际需要去选择使用Buffer还是前边一个章节提到的JsonObject/JsonArray,目前接触的三种数据结构的使用场景在Vert.x中没有任何限制。如果您的应用考虑的是网络传输以及批量操作,您可以考虑优先使用Buffer;如果您的应用考虑的是面向前端呈现、半结构化处理,那么就考虑优先使用Json格式。
1. Netty源码解读(二), http://ifeve.com/netty-2-buffer/, 作者:黄亿华 ↩
2. Java NIO DirectByteBuffer的使用与研究, https://www.cnblogs.com/kesan/p/11224650.html, 作者:柯三 Kesan ↩
3. Java 内存模型, https://blog.csdn.net/silentbalanceyh/article/details/4661230 ↩
4. java.nio.DirectByteBuffer的分配与回收源码剖析, https://blog.csdn.net/mycs2012/article/details/93513057, 作者:Joel.Wang老王 ↩
5. 基于Auth Common开发自定义认证组件, https://www.origin-x.cn/zero-up/2-vertx-tutorial/zvx-001-ji-yuauth-common-kai-fa-vert-x-zi-ding-yi-an-quan-zu-jian.html ↩