JSON
JSON1(JavaScript Object Notation)是一种轻量级的数据交换格式,它是基于ECMAScript2(European Computer Manufactures Association)制定的JS规范的一个子集,采用了完全独立于编程语言的文本格式来存储和表示数据。它是道格拉斯 · 克罗克福德(Douglas Crockford)在2001年推广的一种数据格式,而这位大师是Web开发领域最知名的技术权威,除了JSON,他还创造了JSLint3、JSMin4和ADSafe5规范,JSON这种格式从2005年开始逐渐成为了Web领域里主流的数据格式,它的优点如下:
- 数据格式简单,易于人工读写。
- 这种格式已经是被压缩过的数据格式,在网络传输中占用的带宽比较小。
- 机器解析这种格式也很容易,JavaScript语言中可以使用
eval()对这种格式直接读取。 - 它具有语言独立性,不依赖某种语言,目前主流的计算机语言都支持这种数据格式。
1. 基本格式
JSON的数据格式主要包含两种:
- 键值对集合,也就是通常提到的JSON对象(Json Object)。
- 有序元素集合,也就是通常提到的JSON数组(Json Array)——其实它不仅仅描述数组。
JSON对象通常使用{}(花括号)定义,它是一个无序的键值对集合,每一个键值对使用<key>:<value>的格式描述,而键值对之间则用,分割。例:
{
"name" : "Lang",
"email" : "silentbalanceyh@126.com"
}
JSON数组通常使用[](中括号)定义,它是一个有序的集合,每一个元素都是JSON中支持的一个值,元素和元素之间同样使用,分割。例:
[
"Lang",
33,
true,
{
"language" : "java",
"address" : "CQ"
}
]
上述两种格式中,读者最需要理解的是:值(value)。在JSON对象格式中,值就是每一个键值对的“右值”,而在JSON数组中,值则是每一个元素本身,并且JSON数组并不要求每一个元素的数据类型一致,就像上边例子中的数组每一个元素都是不同类型的“值”。
2. 值格式
前边章节了解了JSON的基本数据格式,本章针对JSON中的“值”进一步了解,总体来讲,JSON格式中的值主要包含以下几种:
- JSON对象
- JSON数组
- 字符串
- 数值类型(整数、浮点数、负数)
- 布尔类型(
true和false,包括"true"和"false") - 空(
null,或"null")
上边枚举的所有值就是JSON中可支持的“值”的清单,对于一些特殊的语言像JavaScript可能还会有undefined的值,读者需要知道这些特殊的值在JSON规范中是没有的。
「注」所有规范在某种语言里实现时,都可能面临特殊语言平台对“语义”发生某种协变,协变过后过的“语义”并没有遵循规范,它的目的是让不同的语言平台和规范之间更加兼容。
2.1. JSON对象
JSON对象是一个“键值对集合”,基本格式如:

对象格式需要说明几点:
- 在JSON规范中,明确指出了“键”是字符串类型,也就是带
"的格式,而在某些语言如JavaScript中,它的"是可以省略的,并不是不遵循规范,而是在使用时,语言内置会将这种键转换成字符串类型。 - 上图中的值部分就是清单中的数据类型,其他类型都是不规范的JSON格式。
- 图中所有的符号都必须是英文格式,如果使用了中文格式也会导致JSON格式不规范。
“从前有座山,山里有座庙、庙里有个老和尚在给小和尚讲故事……”如果使用JSON来描述这句话,它的格式可能如下:
{
"type": "Mountain",
"children":{
"type": "Temple",
"children":{
"action": {
"event": "Tell Story",
"from": "56d2ef0b-a722-4cf7-8394-0ad705e5aeb3",
"to": "f2e821a4-13ef-4b07-a979-11115ddb6314"
},
"entities":[
{
"id": "f2e821a4-13ef-4b07-a979-11115ddb6314",
"type": "Monk",
"age": 5
},
{
"id": "56d2ef0b-a722-4cf7-8394-0ad705e5aeb3",
"type": "Monk",
"age": 60
}
]
}
}
}
上边的JSON数据就把一句完整的话描述清楚了,那么我们来仔细看看它是怎么描述的?
- 数据的顶层就是一个“对象”,这个对象就是“山”,但是在现实生活中,山更倾向于一个抽象的“类”,并非对象,所以这里使用了属性
type来描述。 - 根据描述信息:庙是坐落在山上的,而且从
children的格式可以知道,这座山上只有一座庙。 - 最后一句的描述在JSON中定义了两部分内容:行为
action和对象entities。
JSON只是一种数据格式,如果要用数据来描述行为,那么我们需要针对行为进行定义,所以这里有了action节点,而行为本身的“逻辑”应该由解析它的程序来完成,而不是数据来完成。其次庙里有两个和尚,一个是老和尚,一个是小和尚,所以这里使用了JSON数组来描述,并且两个和尚的type都是Monk,但却拥有不同的属性:年龄age和标识id。年龄属性age就描述了两个和尚的特征,而在action定义中,有一个from和to的属性,描述了:谁给谁讲故事。
「思」在面向对象编程中,世界是可以使用对象来描述的(一切皆对象),上述例子一方面为了说明JSON对象的用法,另外一方面让读者对这种抽象有一个直观的认识。软件本身的职责就是为了形式化这个世界,所以工程师应该具有一种嗅觉,就是所见所闻都尝试使用面向对象的方式去诠释,这种思维自然成为了面向对象编程中的一种基本功——即使使用的是JSON这种静态数据结构,同样可以将世界描绘得多姿多彩。
2.2. JSON数组
JSON数组就是一个“元素的集合”,基本格式如:
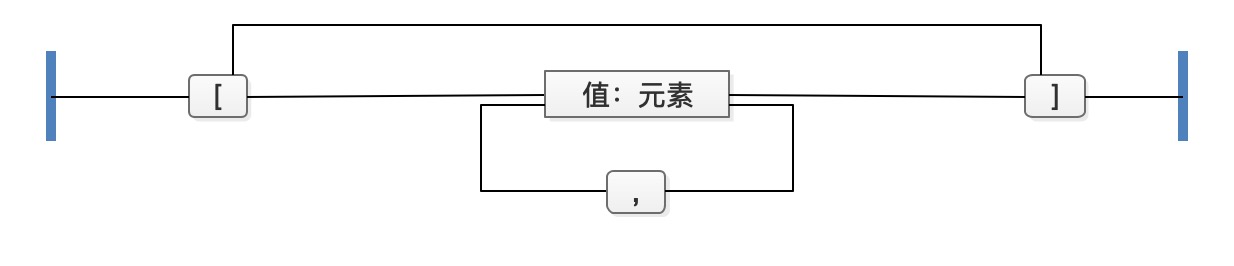 数组格式容易让开发人员产生困惑的就是:如果元素不是JSON对象,那么这个格式还合法么?
这是最让开发人员困惑的一点,因为真正在实际使用场景中,一个JSON数组中元素不同类型的情况不太常用,很多时候项目中我们设计的数据格式往往是每个元素都相同类型,类似于Java语言中的“泛型集合”。但是这里强调一点:即使数组中的元素不是一个JSON对象,即使数组中的每个元素不同类型,它也是一个合法的JSON。例如:
数组格式容易让开发人员产生困惑的就是:如果元素不是JSON对象,那么这个格式还合法么?
这是最让开发人员困惑的一点,因为真正在实际使用场景中,一个JSON数组中元素不同类型的情况不太常用,很多时候项目中我们设计的数据格式往往是每个元素都相同类型,类似于Java语言中的“泛型集合”。但是这里强调一点:即使数组中的元素不是一个JSON对象,即使数组中的每个元素不同类型,它也是一个合法的JSON。例如:
[
"Lang Yu",
true,
12,
{
"address": "重庆市渝中区"
}
]
上述格式也是一个合法的JSON格式,不同于JSON对象的是,这种格式如果用来描述单个对象,那么它的抽象程度对机器解析而言是没有问题的,因为机器内部可以定义它的每一个元素表示什么,而且也可以将元素的顺序固定下来(JSON数组是有序的);但是上边这个格式对开发人员而言,阅读就会存在一定的难度,比如:true表示什么意思?12又表示什么意思?即使如此您也不能否认它是一个合法的JSON数组格式。
「思」定义数据格式时,我们尽可能让“数据说话”,也就是说定义的数据最好是拥有很强的“自描述”性,开发人员可以通过数据本身就知道这段数据所蕴含的“语义”,而不是含糊不清或者只能当做机器格式来阅读。从这点意义上讲,JSON数组用来描述单个对象时,它的语义会有些匮乏,所以真实开发过程中我们往往选择使用JSON数组格式来描述“集合”,而不是“对象”,若要描述一组对象,则可以使用
[{},{}]这种对象数组的格式来实现。
2.3. String
字符串格式是JSON中使用频率最高的值格式,而初学者需要学习的是它的类型,基本格式如下:
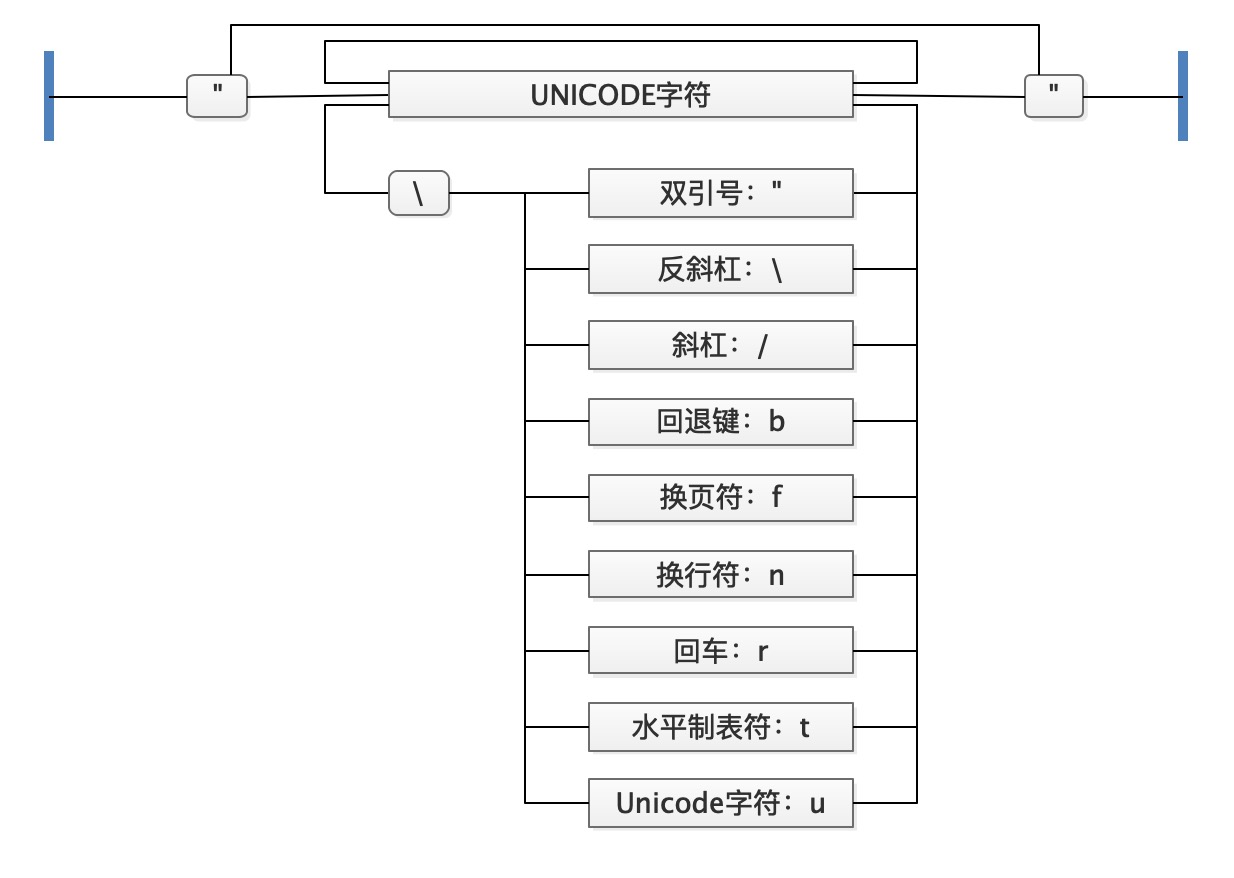
在看字符串类型的值之前,看看官方对字符串的定义:
A string is a sequence of zero or more Unicode characters, wrapped in double quotes, using backslash escapes. A character is represented as a single character string. A string is very much like a C or Java string.
所以有几点需要读者留意:
- 所有的Unicode字符是JSON支持的原生字符集。
- 在字符串必须是被双引号
"修饰的。 - 字符串中不可以包含控制字符,对于特殊的控制字符需要使用转义符(参考图)。
编码历史
计算机只能处理二进制数字,如果要处理文本,就必须将该文本转换成数字才能处理,最早的计算机在设计时使用了8个比特(bit)作为一个字节(byte),所以一个字节能表示的最大整数就是255(11111111),若要表示更大的整数,就必须用更多的字节。全球第一台计算机ENIAC(埃尼阿克,全称Electronic Numerical Integrator And Computer)又称为电子数字积分计算机,它诞生于1946年2月14日的美国宾夕法尼亚大学,由于是美国人发明的,所以最早只有127个字母被编码到计算机中,主要包括:大小写英文、数字和一部分符号,这个编码表就是ASCII码(American Standard Code for Information Interchange)。很显然,ASCII码是无法满足其他国家的需求的,所以之后其他国家为了设计和ASCII码不冲突的编码,有了各自描述自国语言的编码,如:中文的GB2312、日文的Shift_JIS、韩文的Fuc-kr等。
GB2312(《信息交换用汉字编码字符集》,又称:GB2312-80)码是中国国家标准总局在1980年发布,1981年开始实施的国家标准汉字编码字符集,标准号GB2312-1980,它最早在中国大陆、新加坡等地通行,总共收录了6763个汉字和682个图形(7445个字符),总共分94个区,它规定任意一个图形字符采用两个字节表示,每个字节均使用7位编码,习惯上第一个字节称“高字节”,第二个字节称“低字节”。
GBK(《汉字内码扩展规范》)是1995年国家制定的汉字扩展规范GBK1.0,同年12月正式发布实施。它收录了21886个字符,同样分为汉字区和图形符号区,汉字区包含了21003个字符,它向下兼容GB2312编码,它属于GB2312标准基础上的内码扩展规范,使用了双字节编码方案,支持国际标准ISO/IEC10646-1和国家标准GB13000-1中的全部中日韩汉字,还包含了BIG5编码中的所有汉字。
BIG5(又称大五码)是使用繁体中文社区中最常用的电脑汉字字符集标准,收录了13060个汉字。中文的编码分为内码和交换码两类,而BIG5则属于中文内码,这种编码最早在台湾、香港、澳门等繁体中文地区通行,它长期以来并非官方标准,而只是业界标准,Windows繁体中文系统中使用的默认编码就是BIG5。
GB18030(《信息技术中文编码字符集》)标准号GB18030-2005是我国计算机系统必须遵循的基础标准之一,是里程碑事的重要汉字标准,现在很多中文操作系统采用的系统默认编码就是它。该编码有两个版本:GB18030-2000和GB18030-2005。
ISO-8859-1编码是单字节编码,Java开发人员对这种编码不会陌生,它是Tomcat服务器的默认编码。这种编码向下兼容ASCII,字符集支持部分欧洲使用的语言。ISO-8859-1收录的字符除ASCII收录的字符外,还包括西欧语言、希腊语、泰语、阿拉伯语、希伯来语对应的文字符号,欧元符号出现的比较晚,没有被收录在ISO-8859-1当中,这种编码还有一个别名就是Latin1。
区位码、国标码、内码、外码。
「区位码」由于GB2312是一个94 x 94像素的二维表,行则是“区”,列则是“位”,每个汉字都有一个区位的概念,如“浪”的区位是:
32 43,23是高位字节,43就是低位字节,而且区位码使用的是十进制表示。「国标码」就是GB2312,称为“国家标准信息交换用汉字编码”,国标是“中华人民共和国国家标准”的简称,由于它用于在机器内码和外码之间进行转换,所以又称为交换码。如果要将区位码转换成国际码,则必须在“区”和“位”上边分别加上十六进制的
20H即32,也就是说国标码相当于在区位码的基础上向后偏移了32,其目的是防止和ASCII中的不可显示字符和空白冲突(0 ~ 32),如“浪”转换成国标码的方法:32 43转换成16进制为:20 2B,20 2B+20 20得到40 4B的国标码,那么浪的国标码就是40 4B。「内码」国标码虽然可以描述中文,但不能在计算机上直接使用,因为它会和ASCII中的字符冲突,出现乱码,所以为了编避免这种冲突,将国标码中的每个字节最高位从0换成1,即加上128(十六进制的80H),从而得到国标码的“机内码”,又称为“内码”。如“浪”的国标码
40 4B+80 80得到内码C0 CB,此时的汉字和ASCII码就再也不会冲突了。「外码」不论是区位码、国标码都不利于汉字的录入,为了方便汉字录入制定的汉字编码就称为汉字的“外码”,外码和其他三种的区别在于,外码会根据输入法有所区别,常见的外码包括:流水码(区位码)、音码(全拼、简拼、双拼)、形码(五笔、郑码)、音形码(自然码、智能ABC)。
随着计算的普及,美国人意识到ASCII码无法满足很多国家对语言文字编码的需求,所以它们提出了一种全球标准方案来展示世界上所有的字符,于是Unicode码6(Universal Multiple-Octet Coded Character Set)诞生了。它为国际上的每一个字符制定了一个统一标准,而且拥有唯一的数字编号,满足跨语言、跨平台进行文本交换和处理的需求。
综上,编码的演进主要历经了三个核心阶段:
- ASCII码(American Standard Code for Information Interchange),美国信息交换标准码。
- ANSI编码(American National Standards Institute),本地化阶段(如GB2312),使用两个字节来表示各种字符的编码方式称为ANSI编码,不同的本地化ANSI的编码不同。
- Unicode编码(Universal Multiple-Octet Coded Character Set),全球化阶段。
2.4. Number
JSON中的Number类型类似于C和Java中的数值,不支持八进制和十六进制。基本格式如:
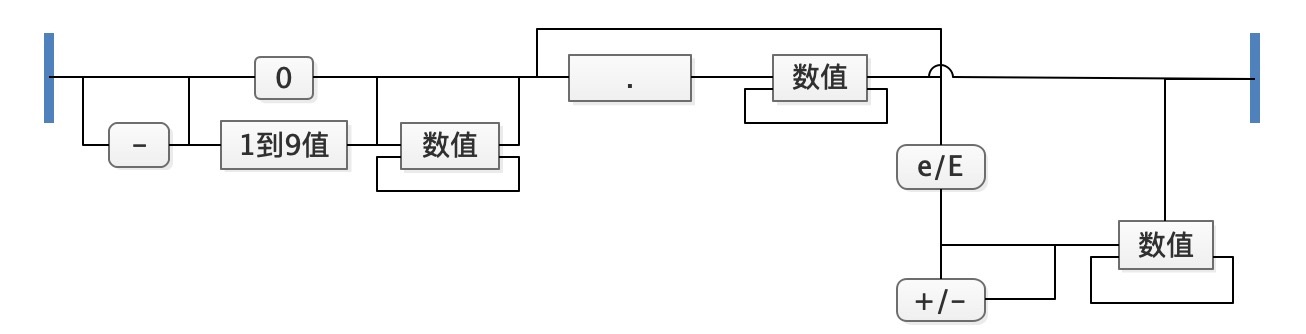
根据上图,总结几点:
- JSON格式中的数值支持负数,直接用
-前缀表示。 - JSON格式支持科学计数法,使用
(+|-)(E|e)的格式处理。
示例如:
{
"age": 12,
"length": 12e+2,
"under": -22,
"money": 345.66
}
Java中的科学计数法
大多数计算器或程序都会使用科学计数法来显示非常大或非常小的结果,子母E或e用来代表十次幂(写作x10b),后边的数字表示它的指数,简单说,任意两个实数a和b(b为整数),aEb表示的是a x 10b。执行下边代码7:
package io.vertx.up._02.json;
public class ETest {
public static void main(final String[] args) {
// 整数部分位数大于等于8开始
System.out.println(1234567.0);
System.out.println(12345678.0);
System.out.println(-12345678.0);
// 整数位为0,当小数位以0开始连续出现大于等于3时开始以科学计数法显示
System.out.println(0.001);
System.out.println(0.0001);
System.out.println(-0.0001);
}
}
运行上述程序会得到:
1234567.0
1.2345678E7
-1.2345678E7
0.001
1.0E-4
-1.0E-4
但在实际使用过程中,程序本身需要统一:要么全部使用科学计数法,要么全部显示成普通计数。
NumberFormat
NumberFormat类(java.text.NumberFormat)是所有数字格式的抽象基类,若输入的小数位数大于设定的最大小数位数,则会执行“四舍五入”,它主要提供格式化和分析数字的接口,并且提供了额外的一些方法,来确定哪些语言环境具有数字格式,以及它们的名称是什么。这个类有助于格式化和分析任何语言环境中的数字,使得代码完全独立于环境对于小数点、千位分隔符或特殊十进制数字的约定。
package io.vertx.up._02.json;
import java.text.NumberFormat;
public class ENumberFormat {
public static void main(final String[] args) {
final NumberFormat nf = NumberFormat.getInstance();
// 设置此格式中不使用分组
nf.setGroupingUsed(false);
// 设置数的小数部分所允许的最大位数
nf.setMaximumFractionDigits(6);
System.out.println(nf.format(10.000015));
System.out.println(nf.format(10.0000107)); // 入
System.out.println(nf.format(10.0000103)); // 舍
}
}
执行上述代码:
10.000015
10.000011
10.00001
DecimalFormat
DecimalFormat是NumberFormat十进制数字格式的具体子类,它比NumberFormat更加方便,具有多种功能,目的在解析和格式化任何语言环境中的数字,包括支持西方、阿拉伯语、印度语数字。它还支持不同类型的数字,包括整数(123)、浮点数(123.4)、科学计数法(1.23E4)、百分比(20%)和货币金额($123)——所有格式都可以本地化。
package io.vertx.up._02.json;
import java.text.DecimalFormat;
public class EDecimalFormat {
static public void SimgleFormat(final String pattern, final double value) {
//实例化DecimalFormat对象
final DecimalFormat myFormat = new DecimalFormat(pattern);
final String output = myFormat.format(value);
System.out.println(value + " " + pattern + " " + output);
}
//使用applyPattern()方法对数字进行格式化
static public void UseApplyPatternMethodFormat(final String pattern, final double value) {
final DecimalFormat myFormat = new DecimalFormat();
myFormat.applyPattern(pattern);
System.out.println(value + " " + pattern + " " + myFormat.format(value));
}
public static void main(final String[] args) {
SimgleFormat("###,###.###", 123456.789);
SimgleFormat("00000000.###kg", 123456.789);
//按照格式模版格式化数字,不存在的位以0显示
SimgleFormat("000000.000", 123.78);
//调用静态UseApplyPatternMethodFormat()方法
UseApplyPatternMethodFormat("#.###%", 0.789);
//将小数点后格式化为两位
UseApplyPatternMethodFormat("###.##", 123456.789);
//将数字转化为千分数形式
UseApplyPatternMethodFormat("0.00\u2030", 0.789);
}
}
运行上述代码8:
123456.789 ###,###.### 123,456.789
123456.789 00000000.###kg 00123456.789kg
123.78 000000.000 000123.780
0.789 #.###% 78.9%
123456.789 ###.## 123456.79
0.789 0.00‰ 789.00‰
3. Java中的Json库
前文讲解了JSON的数据格式的核心内容,这一节将介绍Java语言中的Json序列化/反序列化的常用开源库。Java在处理JSON数据时有四个主流的库:json-lib、jackson、gson、fastjson,这几个库都可以用来处理JSON格式的数据。
3.1. json-lib
这是曾经最广泛使用的JSON解析工具,它在老版本的Java中很受欢迎,它最后的版本停留在了2.4,还提供了JDK91.3和1.5的支持,最后更新时间是2010年,官方网站是:http://json-lib.sourceforge.net/。这个JSON库不太好的地方就是依赖了很多第三方的库如:commons-beanutils.jar、commons-collections-3.2.jar、commons-lang-2.6.jar、commons-logging-1.1.1.jar、ezmorph-1.0.6.jar,而且在复杂类型转换过程中,它对Java Bean10的支持还不太完善,并且在JDK 7中还存在一定的性能问题。
3.2. jackson
Vert.x中内置使用的是Jackson的JSON处理库,它是一个简单的应用库,可以很轻松地将Java对象转换成Json对象或XML(可扩展标记语言,全称:Extensible Markup Language)文档或者进行反序列化。Jackson所依赖的jar包很少,简单易用并且性能不错,这使得Jackson的社区十分活跃,更新速度也很快,它最新的版本是2.9.9,可以直接访问:https://github.com/FasterXML/jackson获取相关源码。它的特点如:
Jackson提供了一个高抽象接口简化了常用的用例,简单易用。- 支持Java Bean的规范时,
Jackson提供了大部分对象的默认序列化/反序列化的功能。 Jackson库是一个经过了市场验证JSON处理库,性能高、快速而且内存占用很低。Jackson库不需要依赖其他第三方的库就可以直接处理,并且处理的数据很干净。
Jackson库处理JSON的方法主要有三种:流式API、树模型、数据绑定。
3.3. gson
不否认,gson是目前功能最全的Json解析神器,它是Google提供的用来在Java对象和JSON数据之间进行映射转换的Java类库,最新版本是2.8.5,它的源代码地址是:https://github.com/google/gson。gson是Google最初在内部使用的工具库,它的主要目标是:
- 提供易于使用的机制和构造函数(工厂方法)将Java转成JSON,反之亦然。
- 允许存在不可修改的对象转换成JSON和从JSON转换出来。
- 允许自定义表示对象。
- 支持任意复杂的对象。
- 生成压缩过不占带宽的JSON输出。
gson在功能完整度上是无可挑剔的,但并不是最快的JSON处理库。
3.4. fastjson
fastjson是用Java语言编写的高性能JSON处理器,如名称fast描述,它性能很高,是阿里巴巴公司开发的。这个JSON库无依赖,也不需要额外的jar,可以直接运行在JDK上。fastjson采用了独创的算法,将解析速度提升到了极致,超过了所有的JSON库,这也是fastjson的目标,它的最新版本是1.2.58,源代码地址:https://github.com/alibaba/fastjson。
3.5. Json库选型
网上有很多文章一直在对比jackson、gson、fastjson三个库究竟谁快,谁性能更高,作者本人并不反对这些评测结果,而且这些结果提供了良好的数据可以让工程师根据自己的实际情况来选择,不过有几个心得需要分享:
- 不混用:在一个独立的项目开发中,不要使用两种不同的JSON处理库,混用很容易导致不同的
jar之间产生一些冲突,导致不可预知的异常。 - 性能:性能是项目开发过程中一个需要追求的永恒指标,但是不是唯一衡量项目成功与否的指标。
- 能驾驭:很多时候不要人云亦云,用自己不擅长的库去做项目开发,除非有强制性的要求,否则用自己的短板去做一个要生产上线的成品是要付出血的代价的。
- 入木四分:使用某个库的过程中,若遇到了很多无法查阅的异常和问题时,可以直接到库内去理解它的原理,真正去掌握这个库的核心。
4. 总结
本章主要讲解了JSON数据格式,Vert.x内部使用了Jackson去处理JSON数据,并定义了自己的数据结构,后边将会对Vert.x中关于JSON数据的轻量级封装进一步讲解,除了自定义的JSON数据结构,Vert.x中在很多地方都是用了JSON数据,包括配置、传输、存储、转换等。 JSON是Vert.x中数据格式的基础,本篇为读者打基础,让初学者能深入理解JSON格式。本章主要内容如下:
- 讲解JSON的基础数据格式、数据类型、值格式内容。
- 介绍Java语言中处理JSON数据格式的常用方式。
1. http://www.json.org ↩
2. 前身为欧洲计算机制造商协会, https://www.ecma-international.org/ ↩
3. 全称JavaScript Code Quality Tool,是检测JavaScript语法规范的工具, http://www.jslint.com/ ↩
4. 全称JavaScript Minifier,是JavaScript代码压缩规范, https://www.crockford.com/jsmin.html ↩
5. 全称Making JavaScript Safe for Advertising,是JavaScript的安全调用规范, http://www.adsafe.org/ ↩
6. Unicode字符, https://baike.baidu.com/item/Unicode/750500?fr=aladdin ↩
7. Java科学计数法, https://www.cnblogs.com/zhanyao/p/6583207.html, 作者:Jenyow ↩
8. 关于Java中DecimalFormat()方法的调用, https://blog.csdn.net/kongchengyeyu/article/details/79720532, 作者:kongchengyeyu ↩
9. 全称Java Development ToolKit,是Java语言开发工具包,整个Java语言的核心,包括了Java运行环境(JRE,Java Runtime Environment)。 ↩
10. 《JavaBean》https://baike.baidu.com/item/javaBean/529577?fr=aladdin ↩