Vertx实例
1.写在遗忘之初
前一个章节已经介绍过Vert.x中的两个基本概念Verticle和Event Bus,从这个章节开始,我们将剥开Vertx实例的面纱。之前我们一直说Verticle实例是使用Vertx实例来发布的,那么Vertx实例是什么?怎么启动Vert.x?也许读者会问:为何要启动?它不就是一个工具集么?是的,它是一个工具集,但Vert.x也提供了可启动的“内嵌容器”,所以通常意义说的启动Vertx实例就是启动Vert.x中提供的容器,当您用Vert.x开发RESTful Web服务时,那么Vert.x就可以充当RESTful Web服务容器1。
1.1. 配置
在启动Vert.x容器之前,先在您的项目中添加如下配置,我们认识的第一个角色叫做:vertx-core,在Maven项目中,您需要在pom.xml文件里添加如下依赖2:
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-core</artifactId>
<version>3.9.0</version>
</dependency>
而在Gradle项目中,则需要在您的build.gradle文件里添加如下依赖:
dependencies {
compile 'io.vertx:vertx-core:3.9.0'
}
1.2. 启动方式
从官方教程可以知道,Vert.x有两种启动方式:编程方式、命令方式,在启动它之前,我们可以看看两种方式各自的优劣,以及分析它们的使用场景。
Vert.x的命令方式启动和SpringBoot的命令方式启动有些区别,SpringBoot中的命令启动方式通常是把程序编译成一个Fat Jar(Java可执行程序),然后通过命令行使用java命令去启动,这种情况下,您依然需要编写SpringBoot中所需的main函数入口,而Vert.x的命令方式不需要编写main函数入口,您只需要编写相关Verticle组件,然后使用vertx命令直接发布Verticle来启动Vertx实例。
「思」我无意于比较SpringBoot生态和Vert.x的生态,那是个人和团队的选择问题,通过概念的对比,会让读者知道各自的原理,更容易各取所需,某些业务场景下,二者确实很相似,其实:软件最忌讳的是信仰主义。SpringBoot是为了市场上使用了Spring的Web以及Web服务项目的快速开发而诞生,而Vert.x不然——它不单是为了Web项目诞生。
希望读者可以明白,与其说把Vert.x当做工具来学,不如说它是一种编程思维的转变,等您学会了Vert.x后,您会恍然大悟:原来程序可以这么写!作为一个求知型的开发者,我会给出最朴实的建议:您要学习的是Vert.x中的事件驱动模型、纯异步编程思维、并行编程、Reactive响应式编程、函数式编程等,而不仅仅是浅尝辄止——当然若您只是想使用Vert.x来做Web类型(特别是RESTful)的项目,您可以自己根据本教程的内容去设计,也可以使用作者开源的Zero3 。
编程方式:
- 需要您书写main函数入口,和SpringBoot一样,并且在main函数中初始化Vertx实例。
- 配置灵活度需要依靠程序本身的设计连接I/O装置如:硬编码模式(HardCoding)、配置管理器、配置文件等来实现,也可使用不同的配置源。
- 自己在启动Vert.x过程中可控粒度更细,从它初始化到启动完成都可以通过编程手段进行控制甚至干扰。
命令方式:
- 不需要您书写main函数,直接可从Verticle的编写开始。
- 简单、直接,对于一些小需求应用尤其合适——比如您的系统仅仅需要一类Verticle做些简单的事情。
- 上手快,不需要借助于理解太多和
Vertx、VertxOptions、VertxFactory相关的东西,开箱即食。
其实命令方式启动调用了Vertx默认的Launcher来完成整个启动过程。
就像华山派分为剑宗和气宗,这两种方式各有优劣,本人的经验是:如果您的项目(产品)在启动过程中需要做的事情很多,而且您个人又有定制化需求(喜欢DIY的有福了),如您想把配置存储在ZooKeeper、Apollo配置中心,可以选择使用编程方式来启动Vert.x,毕竟这种方式的逻辑属于您,您甚至可以在启动过程加入类似Listener的组件来监控整个Vert.x容器的启动流程。但若您目前是在学习,或者说实现一些复杂度不大的项目时,您可以直接使用命令模式来启动Vertx实例,这样够简单,也很直接。当然您也可以使用命令方式去处理复杂度很大的项目,但是这种模式就需要您的“配置管理”技能足够驾驭得住后期的各种扩展。
2.编程方式启动
接下来我们先看看编程方式如何启动Vert.x,如果您选择了编程方式,那么您需要意识到的一点就是一些参数的设置是需要您自己去处理的,而不能依靠命令行那样的方式直接传入JSON了。官方开场白:
You can’t do much in Vert.x-land unless you can communicate with a Vertx object!
对的,如果您想要在Vert.x大陆中干更多的事,那么您的任务就是和Vertx对象谈话,这里的Vertx就表示Vertx实例(io.vertx.core.Vertx类创建的实例,后边统一使用Vertx实例)——“逐陆记”一词就来源于此。编程方式会让您将Vertx对象嵌入到您的应用中,而且您可以直接使用,并进行细粒度控制。
2.1. 直接创建
在您的程序中,可直接使用下边代码来创建Vertx实例:
// 使用默认配置
final Vertx vertx = Vertx.vertx();
// 除开上述默认配置以外,还可以使用带配置项的初始化方式
final Vertx vertx = Vertx.vertx(new VertxOptions().setWorkerPoolSize(40));
如此,main函数中就有了一个Vertx实例了,您就可以直接使用Vertx实例的API了,这里先插入一段官方的笔记:
Most applications will only need a single Vert.x instance, but it’s possible to create multiple Vert.x instances if you require, for example, isolation between the event bus or different groups of servers and clients.
对于一些简单的应用而言,一个Vertx实例足够了,但是有时我们会在一个应用中创建多个Vertx实例,那么这个时候就可以通过上述代码创建一个Vertx实例。io.vertx.core.VertxOptions类让您可以对Vertx实例中的某些选项进行定制化,比如高可用(High Availability)、线程池数量(Pool Size)等等。
2.2. 使用Factory
(不推荐)另外一种比较方便的方式是使用io.vertx.core.impl.VertxFactory来初始化Vertx实例,如:
final VertxFactory factory = new VertxFactoryImpl();
final Vertx vertx = factory.vertx();
这样的写法同样可以拿到Vertx实例,但是这样做有一个不太好的地方就是它暴露了Factory的实现类,并且让它变得不可配置。在创建Vertx实例过程中,Vertx.vertx()这种写法底层调用的就是factory.vertx()语句,唯一的区别是这里的Factory实例不是直接通过new的方式创建出来的,而是使用的下边这句代码:
final VertxFactory factory = ServiceHelper.loadFactory(VertxFactory.class);
也就是说,如果使用Factory创建Vertx实例,这个地方的Factory是可以被替换的,而不是直接使用new VertxFactoryImpl()的方式去创建,从这点意义上讲,使用官方文档中的创建方式更“规范”,——所以您可以理解,只有第一种方式出现于官方文档,而不是Factory的方式,因为Factory的方式有另外的用途,况且Vertx.vertx()这种方式创建底层就是使用的Factory。这里重申:最前边提到的不推荐说的是new VertxFactoryImpl这种方式,它固化了Factory并指定了实现,如此您的程序就写死了——而源码内部Factory的创建方法是连接到了Vert.x Service Factory4模块的。
2.3. Cluster模式的Vertx实例
上述Vertx实例的创建是在非集群模式下,Vertx天生支持集群并且可进行横向扩展,您可以选择一个集群管理器5,然后将您创建的多个Vertx实例运行在同一个集群中。如果使用了集群模式,那么Event Bus就变成了“分布式”的,只是在这种情况下,有些地方的编程细节需要小心,比如SharedData、Session等在使用的时候都要考虑使用Cluster模式的API来处理。 综上所述,Vertx的第一次分水岭读者应该都看到了:是选择单点应用模式?还是集群模式运行?如果是使用编程方式启动Vert.x,那么您可能就需要考虑如何处理这个问题,这种模式下,您的Vertx实例配置信息是在您的代码中,而不是通过命令行参数传入的。在集群模式下创建Vertx实例的代码如下:
Vertx.clusteredVertx(new VertxOptions(), handler -> {
final Vertx vertx = handler.result();
vertx.deployVerticle("io.vertx.up._01.block.ThreadIdVerticle",
new DeploymentOptions().setInstances(4));
});
上述代码是在集群模式下创建Vertx实例的模板代码,但实际上它是无法启动的,因为您会收到这样的异常信息:
Exception in thread "main" java.lang.IllegalStateException: \
No ClusterManagerFactory instances found on classpath
这种模式中,您需要提供集群管理器ClusterManager的实现,最简单的添加实现的方法就是在您的pom.xml文件中添加依赖:
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-hazelcast</artifactId>
<version>3.9.0</version>
</dependency>
这样控制台再也不会抛异常,您可以看到下边的输出:
Members [1] {
Member [192.168.30.41]:5701 - 1a26d43b-d803-4131-826c-dc318b477398 this
}
我一直都觉得我是一个刺儿头,因为喜欢挑刺儿,挑自己的,同时也挑别人的!
上边提到了最简单的引入集群管理器的方式,就是在pom.xml中添加依赖,那么我们做个试验:由于Vert.x官方支持四种集群管理器:Hazelcast、Infinispan、Apache Ignite、Apache ZooKeeper,如果引入两个呢?
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-infinispan</artifactId>
<version>3.9.0</version>
</dependency>
<dependency>
<groupId>io.vertx</groupId>
<artifactId>vertx-hazelcast</artifactId>
<version>3.9.0</version>
</dependency>
关于这个问题的答案参考后记中的《Vert.x中的集群管理器6》。
2.4. 如何统一?
细心的读者会发现,单点应用模式的API是同步API,它的调用会返回一个Vertx实例,而集群模式的API是异步API,返回值是void,有没有一种办法通过一个参数直接将两种方式进行切换,并且不影响代码流程呢?这里我不提供最优解,但是至少可以分享Zero中是怎么实现的。统一的目的是什么?实际上就是切换,让Vertx实例在两种模式中可自由切换,并且实现下边的目标:
- 可以通过配置参数来实现Vertx实例在不同模式中的切换(Vert.x中可以直接分离配置文件实现);
- 可以单独开一个“代码区域”去处理集群管理器的问题——不要觉得集群管理器就是一句简单的
new,我们最终的目的是让项目上生产,能扩展能定制的地方在您写启动器时都不要放过; - 可以让Vertx后续发布/撤销Verticle的主逻辑代码统一。
实际上,使用命令
vertx启动也可以通过不同的配置文件来完成这种设计,但这种方式在面对官方不支持的配置中心如Apollo时,无疑需要扩展编写插件实现,更多的工作量在运维上。编程方式最大的好处是可以将很多流程机械化和自动化,即使可以通过配置文件实现的东西,拥有自己逻辑的启动器,也可以划在产品设计的一环,启动器就属于产品的一部分了。
综上,启动器的代码方式可以达到下边这种效果:

有了这样的代码流程,那么您就很容易在启动器中进行替换以及扩展了。
我们拿到Vertx实例的最终目的是去发布/撤销(deploy/undeploy)某些所需的Verticle实例,在使用过程中返回值也许会变得没有意义,您可以使用Future来改写,这里提供一个参考:
先定义一个启动器的接口Launcher
package io.vertx.up._01.lanucher;
import io.vertx.core.Vertx;
import java.util.function.Consumer;
public interface Launcher {
void start(Consumer<Vertx> startConsumer);
}
然后分别写单点模式和集群模式的实现:
SingleLauncher
package io.vertx.up._01.lanucher;
import io.vertx.core.Vertx;
import io.vertx.core.VertxOptions;
import java.util.function.Consumer;
public class SingleLauncher implements Launcher {
@Override
public void start(final Consumer<Vertx> consumer) {
final VertxOptions options = new VertxOptions();
final Vertx vertx = Vertx.vertx(options);
if (null != vertx) {
consumer.accept(vertx);
}
}
}
ClusterLauncher
package io.vertx.up._01.lanucher;
import io.vertx.core.Vertx;
import io.vertx.core.VertxOptions;
import java.util.function.Consumer;
public class ClusterLauncher implements Launcher {
@Override
public void start(final Consumer<Vertx> consumer) {
// 集群管理器设置
final VertxOptions options = new VertxOptions();
// 如果从参数传入则使用input中的ClusterManager,也可以在这里设计逻辑代码,毕竟这是ClusterLancher的职责所在
Vertx.clusteredVertx(options, handler -> {
if (handler.succeeded()) {
final Vertx vertx = handler.result();
if (null != vertx) {
consumer.accept(vertx);
}
} else {
// 不推荐这样写,这个分支应该连接容错系统来处理
final Throwable ex = handler.cause();
if (null != ex) {
ex.printStackTrace();
}
}
});
}
}
有了上述代码作为启动器的主逻辑后,您就可以在代码中继续完成Vertx实例之后的故事了:
package io.vertx.up._01.lanucher;
public class MainLauncher {
public static void main(final String[] args) {
// 哪种模式?
final boolean isClustered = false;
final Launcher launcher = isClustered ? new ClusterLauncher() :
new SingleLauncher();
// 设置Options
launcher.start(vertx -> {
// 执行Vertx相关后续逻辑
// TODO: 主逻辑
});
}
}
上边这种设计有几点需要注意:
- VertxOptions的构造和获取在两个Launcher内部实现,您可以使用您自己的代码来创建
VertxOptions。 - ClusterLauncher内部可包含ClusterManager的设置以及实现细节,针对集群模式您可以单独定义想要使用的ClusterManager。
- 主逻辑代码的
// TODO:部分就是Vertx实例创建完成之后的代码。
2.5. 小结
其实大部分时间,我在使用Vert.x时都是用的编程方式启动Vertx实例,这个过程会让您投入更多的思考,就像写文章一样,所有Verticle从开始到结束的来龙去脉都可以摸得更清楚,如果是从开发完善的将来可能会有很多扩展的系统立场讲,我也推荐读者开发自己的启动器,这样可以把Vert.x的启动细节拿捏得更好。
从生的生,到死的死,从已知到未知,从未知到已知,爱的神秘,灵魂的离奇,宇宙中透露着的是层层的迷。——《梦里花落知多少 · 三毛》
3. 命令方式启动
Vert.x提供了一个命令vertx7,它可以让您从命令行(Linux/Mac或许叫Shell更合适)去启动Vertx实例,如同官方所讲:我们的目的是和Vertx实例交互
The vertx command is used to interact with Vert.x from the command line .
这种情况下,我们不是在Maven项目中的pom.xml里引入Vert.x的依赖,而是直接下载Vert.x的二进制版本,并且将安装目录下的bin目录设置到PATH的环境变量中,并且您需要确保您的JDK环境是已经安装好的。
因为Vert.x是Polyglot的,所以它支持不同的编程语言编写Verticle,最直接运行Verticle实例的方式是vertx run,下边是各种不同语言的Verticle实例的运行命令:
vertx run my-verticle.js
vertx run my-verticle.groovy
vertx run my-verticle.rh
vertx run io.vertx.example.MyVerticle
vertx run io.vertx.example.MVerticle -cp my-verticle.jar
vertx run MyVerticle.java
好吧,枯燥的岁月还是会出现在我们的教程中——虽然我一直尝试着用有趣的方式来阐述vertx run命令的参数,但实在是找不到一种办法可以让这样的过程变得有趣,不过我可以试试,为了照顾Java的读者,在讲述这些内容的过程中,我也只会针对Java语言进行详细阐述,其他语言就蜻蜓点水的一笔略过了。
3.1. 配置文件
通常在使用vertx run命令时,后边的参数会跟上一个可以找到的Verticle实例的名称,而vertx run命令在执行时,这个过程会执行Vert.x的发布动作,这个动作帮助我们完成Verticle的发布。如前文提到的一个Vertx实例会有一个VertxOptions一样,每个Verticle在发布时都会有一个对应的配置项和它关联,只是很可惜,这个配置项的名字不叫~~VerticleOptions~~,而是叫做DeploymentOptions(io.vertx.core.DeploymentOptions类)。命令方式启动时,DeploymentOptions配置项可以和一个外部的JSON配置文件绑定,这个文件中的配置项会被构造成DeploymentOptions并且传给Vertx实例,它会按照文件中的信息来发布这个Verticle——准确说是这一类的Verticle。
- -conf <config_file>:此配置文件不关心文件后缀名,只关心文件本身的内容,它的内容格式是JSON格式即可。
一份完整的Verticle的配置文件应该如下:
{
"name":"Verticle的名称",
"config":"扩展配置,Json格式",
"extraClasspath":"对应参数-cp,当前隔离组的类路径",
"ha":"对应参数-ha,是否开启高可用功能",
"instances":"对应参数-instances,当前Verticle发布的实例数量",
"isolatedClasses":"隔离组的类信息,用于表示当前Verticle所在的隔离组中有哪些可被类加载器加载到的类",
"isolationGroup":"隔离组的名称,分类的依据",
"worker":"区分当前Verticle是一个Worker还是一个Standard类型的Verticle",
"maxWorkerExecuteTime":"worker=true,若是一个Worker类型则表示该Worker的执行时间上限",
"multiThreaded":"worker=true,对于一个Worker类型的Verticle用来区分它是否是一个Multi-Thread Worker",
"workerPoolName":"worker=true,当前Verticle所在的Worker Pool线程池的名称",
"workerPoolSize":"worker=true,设置Verticle所在的Worker Pool线程池的大小"
}
3.2. 分类和数量
在vertx run命令中,Verticle的分类按照下图执行分流,也就是前文《1.2.Vert.x基础》提到的三次分水岭:
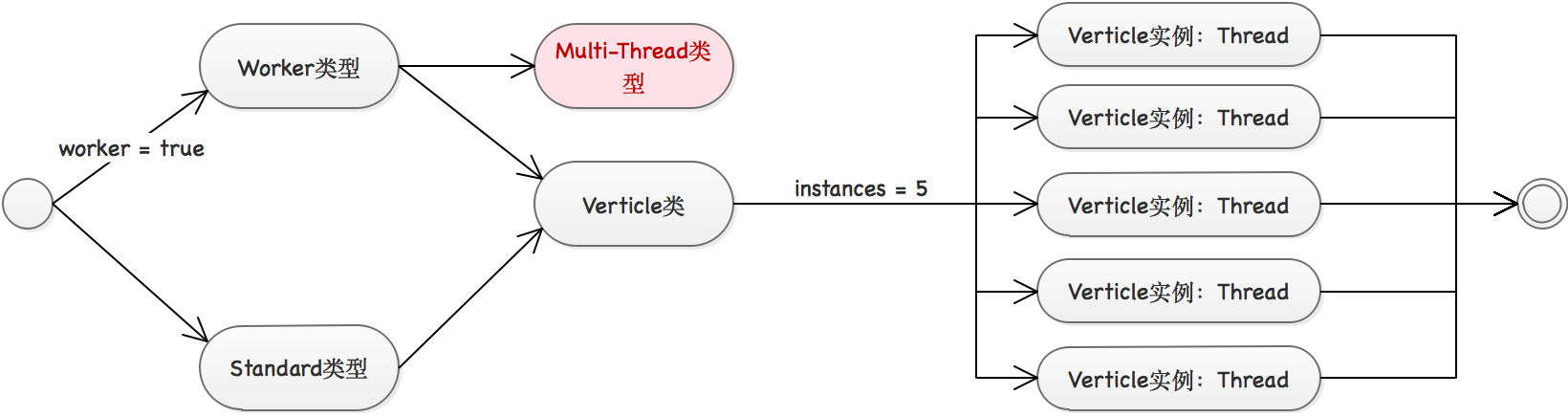 从上图可以知道,真正控制这种分类的核心参数有两个:
从上图可以知道,真正控制这种分类的核心参数有两个:worker和instances,参数worker用于判断当前的Verticle实例是一个Standard类型还是Worker类型,而instances参数则可以设置您要发布的Verticle的数量,一个数量对应一个线程。
如果使用命令方式启动,则无法设置Multi-Thread Worker类型的Verticle,这点尤其注意。上述两个参数,对应到命令行中:
-worker:该参数用于判断当前这一类Verticle实例的类型,也就是上图中区别Standard和Worker的核心标志,这里可以提前说一点Standard类型的Verticle运行的线程池就是Event Loop线程池,而Worker类型的Verticle的线程池并不是在Event Loop中,而是在Worker Pool线程池中。
-instances <instances>:该参数告诉Vertx实例,当前这一类(您所编写的某个Verticle类)的实例数量,除了
Multi-Thread类型的线程数量不好计算,如果是Standard类型和Worker类型的Verticle,这个参数就代表了最终运行的线程数。
3.3. 依赖
在您编写Verticle的过程中,很多第三方的功能您不会自己来编写,比如您使用了阿里云的短信服务,或者使用了Feign Client调用远程的Web Service,面对这样的情况,若您从命令行启动该Verticle,您是需要提供额外的参数的,否则会让开发人员看到异常界的老朋友:Class Not Found。
- -cp <path>:(或-classpath)该参数用于查找当前Verticle依赖的资源文件,这些资源文件包括第三方依赖Java类、配置文件等。和JVM一样,它的默认类路径是
.(当前目录),若您想要指定其他的,那么您需要按照JVM中classpath的设置方式去设置,每个路径的分隔符因操作系统而有所差异,Windows操作系统使用分号;,而Linux/Mac操作系统使用冒号:,这个参数对于Java开发人员而言,应该算是最熟悉的了。
有一种设置资源文件的暴力做法,就是将依赖的资源文件(如jar文件)放到系统类路径中,这样的做法很多时候会破坏系统类加载器,而且在发布当前Verticle后,有可能会影响到其他Verticle的发布,鉴于此,请坚决地SAY NO!(不要这样玩儿)
3.4.集群
和官方教程不同的地方在于本书对命令行参数进行了分类,我也尝试尽量用最好的方式去分类,这样更方便读者记忆。
vertx run命令和集群相关的参数有三个:
- -cluster:(默认false)该参数用于表示发布当前Verticle实例的Vertx实例是否以集群模式运行,若使用了集群模式,那么这些运行在Vertx实例中的Verticle实例会共享一个分布式Event Bus。
- -cluster-port:cluster=true(默认0),该端口号用于两个Vertx实例之间进行集群通信,默认值0表示随机选择一个空闲的端口(
choose a free random port),官方建议是除非您需要特别指定端口,一般情况下该参数可以不设置。 - -cluster-host:cluster=true,该host信息用于两个Vertx实例之间进行集群通信,默认情况下,它会从您可用的网络接口中选择一个,若您有多个网卡,那么您可直接指定使用哪个网络接口。
如我的机器中有:
gif0: flags=8010<POINTOPOINT,MULTICAST> mtu 1280
stf0: flags=0<> mtu 1280
XHC20: flags=0<> mtu 0
XHC0: flags=0<> mtu 0
XHC1: flags=0<> mtu 0
en0: flags=8863<UP,BROADCAST,SMART,RUNNING,SIMPLEX,MULTICAST> mtu 1500
ether 78:4f:43:71:b2:c9
inet6 fe80::c50:1b04:2ad7:a451%en0 prefixlen 64 secured scopeid 0x8
inet 192.168.30.41 netmask 0xffffff00 broadcast 192.168.30.255
nd6 options=201<PERFORMNUD,DAD>
media: autoselect
status: active
p2p0: flags=8843<UP,BROADCAST,RUNNING,SIMPLEX,MULTICAST> mtu 2304
ether 0a:4f:43:71:b2:c9
media: autoselect
status: inactive
awdl0: flags=8943<UP,BROADCAST,RUNNING,PROMISC,SIMPLEX,MULTICAST> mtu 1484
ether be:6a:2e:f3:78:06
inet6 fe80::bc6a:2eff:fef3:7806%awdl0 prefixlen 64 scopeid 0xa
nd6 options=201<PERFORMNUD,DAD>
media: autoselect
status: active
那么我的理解,它会从status = active的网卡中找到可用的host,如上边的192.168.30.41来作为集群通信的host地址,除非您特殊指定,否则这个选择权将递交给Vert.x;若您使用的是Hazelcast集群管理器,在启动的日志中就可以看到它最终选择的Host:
Members [1] {
Member [192.168.30.41]:5701 - eff849df-f298-4d9d-8d2d-e583eebf4055 this
}
3.5.高可用
Vert.x集群支持高可用的功能,对于这些功能,可以使用下边几个参数来设置:
- -ha:指定当前Verticle实例是否使用高可用HA的模式发布;
- -quorum:ha=true时生效,当HA功能开启时,用于指定一个HA的发布(HA DeploymentID)在集群中的最小节点数,默认为0;
- -hagroup:ha=true时生效,如果多个节点构成了一个HA的组,该参数用于指定这些节点所在组的名称,一个Vert.x的集群中可以包含多个HA的组。——只有同一个HA的组中的节点可执行failover故障转移的功能,默认值为
__DEFAULT__
关于HA的详细内容,后边会用单独的章节来说明。
4. 小结
本章介绍了Vertx实例,重心在于Vertx实例的创建过程,通过编程方式和命令方式初始化、启动一个Vertx实例是我们在最初使用Vert.x时必须做的,而读者需要了解更多的是所有Vert.x中的组件都有Options,不同的组件对应不同的Options,并且这些Options在Vert.x内部都可以使用XXConverter和JSON格式的数据相互转换。本节使用的Option是VertxOptions。最后介绍了命令模式中发布Verticle时DeploymentOptions的部分参数,完结了这一小节内容后,我们就开始进入Verticle的正章,是的,到这里Vertx实例就再也没有什么可以详细描述的了,至于Vertx实例是什么相信读者也了然于心了。
1. http://vertx.io/docs/vertx-core/java/ ↩
2. 写本书时最新的版本为3.9.0,不知道写完时会升级到哪个版本。 ↩
3. Zero Framework, http://www.vertxup.cn, 作者写的一个基于Vert.x的RESTful应用框架。 ↩
4. Service Factory, http://vertx.io/docs/vertx-service-factory/java/ ↩
5. Cluster, http://vertx.io/docs/#clustering ↩
6. 「Vert.x中的集群管理器」 https://www.origin-x.cn/zero-up/5-vertx-land/zbr-003-vertxzhong-de-ji-qun-guan-li-qi.html ↩
7. http://vertx.io/docs/vertx-core/java/#_the_vertx_command_line ↩